PeerTube 4.1 das Opensource Videoportal ist veröffentlicht worden.
Das ist an sich eine sehr tolle Nachricht. Auch dass manche Funktionen standardmäßig ausgeschaltet werden können. Wie zum Beispiel das P2P Protokoll, das die Bandbreitenlast vom anbietenden Server zwischen den KonsumentInnen aufteilen kann.
Was an sich eine sehr solidarische Funktion ist, ist im Gegenzug natürlich auch ein Privatsphärenproblem. Darüber sollten wir anfangen eine gesellschaftliche Diskussion zu führen, ohne dass die großen Konzerne in Altherren und -damen Manier “hörthört” grunzen.
Zuallererst sei vorangestellt: Privatssphäre ist wichtig! Aber darauf folgt ein sehr dickes ABER. Viele der extremen PrivatsphärenverferchterInnen blockieren mit ihrem Verhalten eine Ausbreitung des Schutzes der Privatsphäre!
Die Zwei Finanzierungs-Aspekte leiten mich zu dieser Aussage
Die Person die Geld investiert, um diesen Service zur Verfügung zu stellen
Die Person, die die Inhalte zur Verfügung stellt.
Wir alle haben es gerne und dankend angenommen, dass “Internet” und alle damit zusammengehörigen Dienste für die Allgemeinheit wenig bis gar nichts kostet (kostenlos). Dafür haben Konzerne neue Wege gefunden “kostenlos” so gewinnbringend zu vermarkten, dass selbst die Hölle vor Neid erblasst.
Übersetzt heißt das “kostenlos gewinnbringend": wir bezahlen dafür.
Wir bezahlen dafür vielleicht nicht direkt mit Geld, aber indirekt schon mit Geld. Es gibt genügend Beispiele die das beweisen (Schufa, Cambridge Analytica, uvm).
Dienste die von irgendjemand bereit gestellt werden kosten Geld. Ob diese Dienste ein laufendes System sind, oder ob diese Dienste Ergebnisse von Recherchen, oder Zusammenfassungen sind, die uns interessieren. Wir haben ein Interesse solche Dienste in Anspruch zu nehmen und es wäre extrem egozentrisch, sich auf den Standpunkt zu stellen, dass man einen kostenlosen Anspruch darauf hätte!
Im Gegenzug darf man sich aber auch nicht beschweren, wenn bei ausbleibendem Support der Anbieter sich eine Finanzierungsquelle sucht. Egal ob es um die Erhaltung des Dienstes, oder eine Gewinnerzielungsabsicht trägt. Eine Diskussion darum ist eine reine Neiddebatte, die es nicht gäbe, wenn wir so einen Dienst überhaupt nicht wollten.
Daher mein Aufruf an alle PrivatspährennutzerInnen: Wenn ihr Dienste in Anspruch nehmt, die die Privatspähre schützen wollen, dann sehr euch auch in der Pflicht etwas dafür zu tun. Das heißt nicht immer Geld. Aber das heisst IMMER bezahlen.
Das umschließt auch die sogenannten Datenkraken, bei denen ebenso von ContentanbieterInnen konsumiert wird. Dort ist das Zahlungsmittel Likes, Abos und vor allem Kommentare. Der Algorithmus ist das Transaktionssystem!
Wenn ihr als PrivatspährennutzerInnen also den Menschen nicht schaden wollt, die für euch wichtige oder interessanten Dienste oder Content zur Verfügung stellen, dann seid fair und beraubt sie nicht, um das finanzielle Fundament, dass das erst möglich macht!
Nach über zwei Jahren Entwicklungszeit konnte Tomas Matejicek eine neue Version der Live-Distribution Slax veröffentlichen.
Ursprünglich basierte Slax, wie der Name nahelegen kann, auf Slackware. 2017 entschied sich der Entwickler jedoch auf Debian GNU/Linux als Basis zu wechseln.
Slax ist primär zur Nutzung als Live-System geeignet, unterscheidet sich jedoch von vielen anderen Distribution dadurch, dass mittels aufs eine Persistenz realisiert wurde.
Letzteres erwies sich bei der Portierung auf die aktuelle Debian 11 Version (Codename Bullseye) allerdings als grössere Hürde, da Debian standardmässig nur noch overlayfs unterstützt.
Erste Versuche mit overlayfs zeigten jedoch, dass ich damit nicht ohne weiteres der von Slax gewohnte Komfort, wie das automatische Applizieren von Änderungen, realisieren lies.
Dies bewog Tomas dazu einen eigenen angepassten Kernel mit aufs Unterstützung zu verwenden.
Darüber hinaus wird Chromium nicht mehr standardmässig ausgeliefert, lässt sich allerdings weiterhin mit wenigen Klicks installieren.
Zur Netzwerkverwaltung kommt neu connman statt wicd zum Einsatz und scite ist der Standard-Texteditor.
Die Slackware Distribution unterstützt schon seit einiger Zeit die Installation auf EFI-basierten Systemen mithilfe des Installationsprogramms. Die Einrichtung einer verschlüsselten Partition ist allerdings eine manuelle Vorbereitung notwendig.
Nach dem Start von dem Installationsmedium in UEFI-Modus sollte zunächst das Tastaturlayout definiert werden.
In der Konsole kann daraufhin die Festplatte partitioniert werden. Im Folgenden gehen wir davon aus, dass die gesamte Festplatte für die Slackware Installation zur Verfügung steht.
Zur Erstellung des Partitionslayouts kann cfdisk verwendet werden, welches initial mit der Option -z gestartet werden sollte. Die Device-Nodes müssen dabei an die lokalen Gegebenheiten angepasst werden.
cfdisk -z /dev/sda
Als Partitionslabel sollte gpt gewählt werden.
Zunächst wird eine unverschlüsselte EFI Boot-Partition mit einer empfohlenen Grösse von 512MB erstellt.
Im verbleibenden Speicherplatz wird eine Partition des Typs Linux LVM angelegt.
Nach dem Speichern der Änderungen kann cfdisk verlassen werden.
Nun erfolgt die eigentliche LUKS-Einrichtung.
Zunächst wird die Partition entsprechend formatiert. Während des Systemstarts wird standardmässig das US-Tastaturlayout verwendet. Daher sollte zu diesem Zeitpunkt ein Passwort verwendet werden, welches auch mit diesem Layout gut zu nutzen ist.
Alternativ kann eine angepasste initrd mithilfe von mkinitrd und der Angabe des Parameters -l KeyboardLayout erstellt werden. Beispiel -l sg-latin1 für Schweizerdeutsch.
cryptsetup luksFormat /dev/sda2
Dies muss durch die Eingabe von YES bestätigt werden
Daraufhin lässt sich das Volumen wie folgt öffnen:
cryptsetup open /dev/sda2 slackware
In diesem können nun die Logical Volumes erstellt werden. Üblicherweise wird dort zunächst ein Physical Volume definiert.
pvcreate /dev/mapper/slackware
Daraufhin kann eine Volume Group angelegt werden:
vgcreate slackwarevg /dev/mapper/slackware
In dieser lassen sich die eigentlichen Logical Volumes erstellen. Dabei wird in diesem Beispiel eine SWAP Partition von 4G Grösse angelegt und der verbleibende Speicherplatz als Root-Partition genutzt:
Abschliessen kann die eigentliche Installation von Slackware mithilfe des setup Befehls gestartet werden.
Es ist dabei wichtig zu beachten, dass das richtige Volumen als Root Partition ausgewählt wird (/dev/mapper/slackwarevg-root) und elilo statt lilo installiert wird.
übersetzt die wichtigsten -Mathe-Notationen in HTML. Es ist dabei schneller als MathJax, hat im Gegenzug aber noch nicht (sooooo) viele Notationen umgesetzt wie der Platzhirsch. Zudem unterscheidet sich die Anwendung in Blogdown und HUGO.
KaTeX in HUGO einbinden
In meinem Themeordner erstelle ich die Datei /MEINTHEME/layouts/partials/katex.html und gebe ihr folgenden Inhalt:
<link rel="stylesheet" href="https://cdn.jsdelivr.net/npm/katex@0.15.2/dist/katex.min.css" integrity="sha384-MlJdn/WNKDGXveldHDdyRP1R4CTHr3FeuDNfhsLPYrq2t0UBkUdK2jyTnXPEK1NQ" crossorigin="anonymous"><!-- The loading of KaTeX is deferred to speed up page rendering --><script defer src="https://cdn.jsdelivr.net/npm/katex@0.15.2/dist/katex.min.js" integrity="sha384-VQ8d8WVFw0yHhCk5E8I86oOhv48xLpnDZx5T9GogA/Y84DcCKWXDmSDfn13bzFZY" crossorigin="anonymous"></script><!-- To automatically render math in text elements, include the auto-render extension: --><script defer src="https://cdn.jsdelivr.net/npm/katex@0.15.2/dist/contrib/auto-render.min.js" integrity="sha384-+XBljXPPiv+OzfbB3cVmLHf4hdUFHlWNZN5spNQ7rmHTXpd7WvJum6fIACpNNfIR" crossorigin="anonymous" onload="renderMathInElement(document.body);"></script><script>document.addEventListener("DOMContentLoaded",function() {renderMathInElement(document.body, {delimiters: [ {left:"$$",right:"$$",display:true}, {left:"$",right:"$",display:false} ] }); });</script>
Ihr solltet nachschauen, ob die Version 0.15.2 immer noch die aktuellste ist und ggfs. die Zeilen entsprechend anpassen.
In der Datei /MEINTHEME/layouts/partials/head.html ergänze ich:
{{ if .Params.math }}{{ partial "katex.html" . }}{{ end }}
Wenn ich später in Blogdown bei einem Post im Meta-Kopf folgenden Paramter setze:
math:true
…dann wird KaTeX geladen und kann verwendet werden. Die Informationen hierzu hab ich in Mert Bakirs Blog gefunden.
Beispiele
Die Anwendung unterscheidet sich, je nachdem, ob .md, .Rmarkdown oder .Rmd-Files verwendet werden.
.md
In einfachen Markdowndokumenten funktioniert die Inline-Verwendung mittels Dollarzeichen:
Dies ist ein Text mit $E=m\cdot c^2$
Das ergibt:
Dies ist ein Text mit
Das funktioniert auch mit Sonderzeichen:
Wir verwenden $\LaTeX\rightarrow\KaTeX$ und das klappt ganz gut
Das ergibt:
Wir verwenden und das klappt ganz gut
Mathe-Umgebungen werden mit zwei Dollarzeichen eingerahmt:
$$E=m\cdot c^2$$
Das ergibt:
Mit dem align-Environment werden die Formelzeilen automatisch am rechten Rand durchnummeriert. Environments müssen nicht per Dollarzeichen eingeführt werden sondern funktioniert direkt im Text :
Dies ist eine Formel\begin{align}E=m\cdot c^2\end{align}und ich finde sie gut
Das ergibt:
Dies ist eine Formel \begin{align} E=mc^2 \end{align} und ich finde sie gut
So funktioniert auch das equation-Environment direkt im Text:
Einstein hat mal gesagt:\begin{equation}E=m\cdot c^2\end{equation}und ich glaube, er hatte Recht
Das ergibt:
Einstein hat mal gesagt:
\begin{equation} E=mc^2 \end{equation}
und ich glaube, er hatte Recht
Eine Übersicht aller unterstützer Environments findet ihr hier.
.Rmarkdown
In .Rmarkdown-Files ist die Notation leicht anders. So müssen bei der Inline-Verwendung die Dollarzeichen mittels Backslash auskommentiert werden:
Dies ist ein Text mit \$a^2 + b^2 = c^2\$
Das ergibt:
Dies ist ein Text mit
Das gilt auch für alle Sonderzeichen:
Wir verwenden \$\\LaTeX \\rightarrow \\KaTeX\$ und das klappt ganz gut
Das ergibt:
Wir verwenden und das klappt ganz gut
Mathe-Umgebungen werden wie gewohnt mit zwei Dollarzeichen eingerahmt.
$$a^2 + b^2 = c^2$$
Das ergibt:
Auch hier müssen die Backslashs von Sonderzeichen auskommentiert werden:
$$\\LaTeX \\rightarrow \\LaTeX$$
Das ergibt:
In .Rmarkdown-Files müssen bei allen Environments und Sonderzeichen die \ von \begin{} und \end{} auskommentiert werden, damit sie direkt im Text funktionieren. Für das align-Environment sieht das dann so aus:
Irgendwas mit Dreiecken\\begin{align}a^2 + b^2 = c^2\\end{align}Was war das noch?
Das ergibt:
Irgendwas mit Dreiecken \begin{align} a^2 + b^2 = c^2 \end{align} Was war das noch?
Genau so funktioniert auch das equation-Environment:
Pythagoras hat mal gesagt:\\begin{equation}a^2 + b^2 = c^2\\end{equation}und ich glaube, er hatte Recht
Das ergibt:
Pythagoras hat mal gesagt:
\begin{equation} a^2 + b^2 = c^2 \end{equation}
und ich glaube, er hatte Recht
Eine Übersicht aller unterstützer Environments findet ihr hier.
.Rmd
In .Rmd-Dokumenten funktioniert die Inline-Verwendung wieder mittels Dollarzeichen:
Dies ist ein Text mit $\Reals\backsim 2^\N$
Das ergibt:
Dies ist ein Text mit
Das funktioniert auch mit Sonderzeichen:
Wir verwenden $\LaTeX\rightarrow\KaTeX$ und das klappt ganz gut
Das ergibt:
Wir verwenden und das klappt ganz gut
Mathe-Umgebungen werden mit zwei Dollarzeichen eingerahmt:
$$\Reals\backsim 2^\N$$
Das ergibt:
Mit dem align-Environment werden die Formelzeilen automatisch am rechten Rand durchnummeriert. Environments müssen nicht mit Dollarzeichen eingerahmt werden, sondern funktionieren direkt im Text:
Was war das noch für eine Formel\begin{align}\Reals\backsim 2^\N\end{align}Und was bedeutet sie?
Das ergibt:
Was war das noch für eine Formel \begin{align} \mathbb{R} \backsim 2^N \end{align} Und was bedeutet sie?
Das equation-Environment funktioniert genau so:
Cantor hat mal gesagt:\begin{equation}\Reals\backsim 2^\N\end{equation}und ich glaube, er hatte Recht
Das ergibt:
Cantor hat mal gesagt: und ich glaube, er hatte Recht
Eine Übersicht aller unterstützer Environments findet ihr hier.
Allgemein
Zeilenumbrüche funktionieren per \newline, aber nicht mit \\:
\begin{align} E &= m \cdot c^2 \newline a^2 + b^2 &= c^2 \newline\Reals &\backsim 2^\N\end{align}
Das ergibt:
Das Prozentzeichen muss mit zwei Backslashs auskommentiert werden:
übersetzt die wichtigsten -Mathe-Notationen in HTML. Es ist dabei schneller als MathJax, hat im Gegenzug aber noch nicht (sooooo) viele Notationen umgesetzt wie der Platzhirsch. Zudem unterscheidet sich die Anwendung in Blogdown und HUGO.
KaTeX in HUGO einbinden
In meinem Themeordner erstelle ich die Datei /MEINTHEME/layouts/partials/katex.html und gebe ihr folgenden Inhalt:
<linkrel="stylesheet"href="https://cdn.jsdelivr.net/npm/katex@0.15.2/dist/katex.min.css"integrity="sha384-MlJdn/WNKDGXveldHDdyRP1R4CTHr3FeuDNfhsLPYrq2t0UBkUdK2jyTnXPEK1NQ"crossorigin="anonymous"><!-- The loading of KaTeX is deferred to speed up page rendering --><scriptdefersrc="https://cdn.jsdelivr.net/npm/katex@0.15.2/dist/katex.min.js"integrity="sha384-VQ8d8WVFw0yHhCk5E8I86oOhv48xLpnDZx5T9GogA/Y84DcCKWXDmSDfn13bzFZY"crossorigin="anonymous"></script><!-- To automatically render math in text elements, include the auto-render extension: --><scriptdefersrc="https://cdn.jsdelivr.net/npm/katex@0.15.2/dist/contrib/auto-render.min.js"integrity="sha384-+XBljXPPiv+OzfbB3cVmLHf4hdUFHlWNZN5spNQ7rmHTXpd7WvJum6fIACpNNfIR"crossorigin="anonymous"onload="renderMathInElement(document.body);"></script><script>document.addEventListener("DOMContentLoaded",function() {renderMathInElement(document.body, {delimiters: [ {left:"$$",right:"$$",display:true}, {left:"$",right:"$",display:false} ] }); });</script>
Ihr solltet nachschauen, ob die Version 0.15.2 immer noch die aktuellste ist und ggfs. die Zeilen entsprechend anpassen.
In der Datei /MEINTHEME/layouts/partials/head.html ergänze ich:
{{ if .Params.math }}{{ partial "katex.html" . }}{{ end }}
Wenn ich später in Blogdown bei einem Post im Meta-Kopf folgenden Paramter setze:
math:true
…dann wird KaTeX geladen und kann verwendet werden. Die Informationen hierzu hab ich in Mert Bakirs Blog gefunden.
Beispiele
Die Anwendung unterscheidet sich, je nachdem, ob .md, .Rmarkdown oder .Rmd-Files verwendet werden.
.md
In einfachen Markdowndokumenten funktioniert die Inline-Verwendung mittels Dollarzeichen:
Dies ist ein Text mit $E=m\cdot c^2$
Das ergibt:
Dies ist ein Text mit
Das funktioniert auch mit Sonderzeichen:
Wir verwenden $\LaTeX\rightarrow\KaTeX$ und das klappt ganz gut
Das ergibt:
Wir verwenden und das klappt ganz gut
Mathe-Umgebungen werden mit zwei Dollarzeichen eingerahmt:
$$E=m\cdot c^2$$
Das ergibt:
Mit dem align-Environment werden die Formelzeilen automatisch am rechten Rand durchnummeriert. Environments müssen nicht per Dollarzeichen eingeführt werden sondern funktioniert direkt im Text :
Dies ist eine Formel\begin{align}E=m\cdot c^2\end{align}und ich finde sie gut
Das ergibt:
Dies ist eine Formel \begin{align} E=mc^2 \end{align} und ich finde sie gut
So funktioniert auch das equation-Environment direkt im Text:
Einstein hat mal gesagt:\begin{equation}E=m\cdot c^2\end{equation}und ich glaube, er hatte Recht
Das ergibt:
Einstein hat mal gesagt:
\begin{equation} E=mc^2 \end{equation}
und ich glaube, er hatte Recht
Eine Übersicht aller unterstützer Environments findet ihr hier.
.Rmarkdown
In .Rmarkdown-Files ist die Notation leicht anders. So müssen bei der Inline-Verwendung die Dollarzeichen mittels Backslash auskommentiert werden:
Dies ist ein Text mit \$a^2 + b^2 = c^2\$
Das ergibt:
Dies ist ein Text mit
Das gilt auch für alle Sonderzeichen:
Wir verwenden \$\\LaTeX \\rightarrow \\KaTeX\$ und das klappt ganz gut
Das ergibt:
Wir verwenden und das klappt ganz gut
Mathe-Umgebungen werden wie gewohnt mit zwei Dollarzeichen eingerahmt.
$$a^2 + b^2 = c^2$$
Das ergibt:
Auch hier müssen die Backslashs von Sonderzeichen auskommentiert werden:
$$\\LaTeX \\rightarrow \\LaTeX$$
Das ergibt:
In .Rmarkdown-Files müssen bei allen Environments und Sonderzeichen die \ von \begin{} und \end{} auskommentiert werden, damit sie direkt im Text funktionieren. Für das align-Environment sieht das dann so aus:
Irgendwas mit Dreiecken\\begin{align}a^2 + b^2 = c^2\\end{align}Was war das noch?
Das ergibt:
Irgendwas mit Dreiecken \begin{align} a^2 + b^2 = c^2 \end{align} Was war das noch?
Genau so funktioniert auch das equation-Environment:
Pythagoras hat mal gesagt:\\begin{equation}a^2 + b^2 = c^2\\end{equation}und ich glaube, er hatte Recht
Das ergibt:
Pythagoras hat mal gesagt:
\begin{equation} a^2 + b^2 = c^2 \end{equation}
und ich glaube, er hatte Recht
Eine Übersicht aller unterstützer Environments findet ihr hier.
.Rmd
In .Rmd-Dokumenten funktioniert die Inline-Verwendung wieder mittels Dollarzeichen:
Dies ist ein Text mit $\Reals\backsim 2^\N$
Das ergibt:
Dies ist ein Text mit
Das funktioniert auch mit Sonderzeichen:
Wir verwenden $\LaTeX\rightarrow\KaTeX$ und das klappt ganz gut
Das ergibt:
Wir verwenden und das klappt ganz gut
Mathe-Umgebungen werden mit zwei Dollarzeichen eingerahmt:
$$\Reals\backsim 2^\N$$
Das ergibt:
Mit dem align-Environment werden die Formelzeilen automatisch am rechten Rand durchnummeriert. Environments müssen nicht mit Dollarzeichen eingerahmt werden, sondern funktionieren direkt im Text:
Was war das noch für eine Formel\begin{align}\Reals\backsim 2^\N\end{align}Und was bedeutet sie?
Das ergibt:
Was war das noch für eine Formel \begin{align} \mathbb{R} \backsim 2^N \end{align} Und was bedeutet sie?
Das equation-Environment funktioniert genau so:
Cantor hat mal gesagt:\begin{equation}\Reals\backsim 2^\N\end{equation}und ich glaube, er hatte Recht
Das ergibt:
Cantor hat mal gesagt: und ich glaube, er hatte Recht
Eine Übersicht aller unterstützer Environments findet ihr hier.
Allgemein
Zeilenumbrüche funktionieren per \newline, aber nicht mit \\:
\begin{align} E &= m \cdot c^2 \newline a^2 + b^2 &= c^2 \newline\Reals &\backsim 2^\N\end{align}
Das ergibt:
Das Prozentzeichen muss mit zwei Backslashs auskommentiert werden:
Die MZLA Technologies Corporation hat mit Thunderbird 91.6.1 ein Update für seinen Open Source E-Mail-Client veröffentlicht.
Neuerungen von Thunderbird 91.6.1
Mit dem Update auf Thunderbird 91.6.1 hat die MZLA Technologies Corporation ein Update außer der Reihe für seinen Open Source E-Mail-Client veröffentlicht und behebt damit mehrere Fehler der Vorgängerversion. Diese lassen sich in den Release Notes (engl.) nachlesen. Dies schließt auch eine geschlossene Sicherheitslücke ein.
In Teil 1 dieser Artikelserie habe ich mein Ansinnen ausführlich beschrieben. Dieser Teil widmet sich der Entwicklung einer Ansible-Rolle zum Deployment des Nextcloud-Apache-Container-Images.
In den folgenden Abschnitten beschreibe ich die Einrichtung eines Python Virtual Environments, die Installation von Ansible in dem zuvor erstellten Environment und die Installation der Ansible-Collection containers.podman, bevor ich mich abschließend der eigentlichen Ansible-Rolle widme.
Damit ist die Installation von ansible-core abgeschlossen. Im folgenden Code-Block wird geprüft, ob Ansible sich grundsätzlich mit dem Zielsystem verbinden und dort einen Python-Interpreter identifizieren kann.
Installation der Ansible-Collection containers.podman
Um Podman auf dem Zielsystem konfigurieren zu können, wird die genannte Ansible-Collection benötigt, welche mit folgendem Befehl installiert werden kann. Der Code-Block zeigt zusätzlich die Ausgabe während der Installation.
(ansible-core2.x) [t14s ansible-core2.x]$ ansible-galaxy collection install containers.podman
Starting galaxy collection install process
Process install dependency map
Starting collection install process
Downloading https://galaxy.ansible.com/download/containers-podman-1.8.2.tar.gz to /home/tronde/.ansible/tmp/ansible-local-8729oh0om8w3/tmp7tv2yrae/containers-podman-1.8.2-9rw3fd1y
Installing 'containers.podman:1.8.2' to '/home/tronde/.ansible/collections/ansible_collections/containers/podman'
containers.podman:1.8.2 was installed successfully
Ansible-Rolle: Deployment von Nextcloud und MariaDB als Pod
Nextcloud benötigt für den Betrieb eine Datenbank. Hierfür könnte man eine integrierte SQLite nutzen. Dies wird jedoch nur für kleine Umgebungen empfohlen. Während der Entstehung dieses Artikels wird MariaDB als Datenbank-Backend vom Nextlcoud-Projekt empfohlen. Daher habe ich mich entschieden, das Nextcloud-Image zusammen mit einem MariaDB-Container zu deployen. Dazu greife ich auf die beiden folgenden Container-Repositorien zurück:
Das Grundgerüst bzw. die Verzeichnisstruktur für die Ansible-Rolle wurde erstellt mit:
$ ansible-galaxy role init --offline ansible_role_deploy_nextcloud_with_mariadb_pod
Die aktuelle Version der Ansible-Rolle ist auf GitHub zu finden. Ich werde ihre Bestandteile hier im Einzelnen vorstellen.
Die Variablen in defaults/main.yml
In der Datei defaults/main.yml habe ich Standardwerte für Variablen definiert, die geeignet sind, eine funktionsfähige Nextcloud-Instanz zu initialisieren. Die Bezeichner der Variablen sind dabei der Dokumentation der verwendeten Container-Repositorien entnommen.
In Zeile 4-7 und 10 werden die Namen für Podman-Volumes definiert, welche die persistent zu speichernden Daten aufnehmen werden.
Die Zeilen 13-17 definieren Variablen für die MariaDB-Instanz, wie z.B. Namen der Datenbank, Benutzername und Passwörter für diese Datenbank und den DB-Host. Diese werden neben dem MariaDB-Container auch von dem Nextcloud-Container benötigt, um eine Verbindung zur Datenbank herstellen zu können.
Zeile 20-22 definiert Variablen, die für den MariaDB-Container benötigt werden. Hier wird z.B. die Version des Container-Images (MARIADB_IMAGE) und ein Name für die Container-Instanz (MARIADB_NAME) festgelegt.
Die folgenden Zeilen widmen sich den Variablen für den Nextcloud-Container. Dort werden in den Zeilen 25 u. 26 Benutzername und Passwort für den Nextcloud-Admin definiert, gefolgt von einigen Variablen, welche bei Nutzung eines Reverse-Proxy benötigt werden und SMTP-Variablen, welche der Nextcloud den Mailversand ermöglichen.
24 # Nextcloud vars
25 NEXTCLOUD_ADMIN_USER: nc_admin
26 NEXTCLOUD_ADMIN_PASSWORD: VSnfD2021!
27 NEXTCLOUD_OVERWRITEPROTOCOL: ""
28 NEXTCLOUD_OVERWRITECLIURL: ""
29 NEXTCLOUD_TRUSTED_DOMAINS: ""
30
31 # SMTP vars
32 SMTP_HOST: smtp.example.com
33 SMTP_SECURE: tls # ssl to use SSL, or tls zu use STARTTLS
34 SMTP_PORT: 587 # (25, 465 for SSL, 587 for STARTTLS)
35 SMTP_AUTHTYPE: LOGIN
36 SMTP_NAME: bob@example.com
37 SMTP_PASSWORD: MailSecret1!
38 MAIL_FROM_ADDRESS: no-reply@example.com
39 MAIL_DOMAIN: "@example.com"
Bei den SMTP-Variablen handelt es sich um Beispiel-Werte. Diese müssen an die konkrete Umgebung angepasst werden.
Es folgen nun noch ein paar Variablen, welche dem Pod und dem Nextcloud-Container einen Namen geben, sowie die Version des zu verwendenden Nextcloud-Container-Images festlegen.
41 # Vars for podman-pod(1)
42 POD_NAME: nc_pod
43 POD_PORT: 127.0.0.1:40231:80
44 POD_INFRA_CONMON_PIDFILE: /tmp/nc_pod_infra.pid
45
46 # Vars for Nextcloud container
47 NC_CONMON_PIDFILE: /tmp/nc_conmon.pid
48 NC_IMAGE: docker.io/library/nextcloud:23-apache
49 NC_NAME: nextcloud
Durch POD_PORT: 127.0.0.1:40231:80 wird definiert, dass der Port 40231 an das Loopback-Interface gebunden und mit Port 80 des Pods verknüpft wird. Mit dieser Einstellung ist die Nextcloud-Instanz nur von dem Host aus erreichbar, auf dem sie ausgebracht wurde. Möchte man sie auch von anderen Hosts aus erreichbar machen, kann man entweder den Teil mit 127.0.0.1: weglassen oder einen Reverse-Proxy wie z.B. NGINX verwenden. Ich empfehle an dieser Stelle letzteres.
Hinweis: In defauts/main.yml stehen Passwörter im Klartext. Diese sind mit der Veröffentlichung der Ansible-Rolle allgemein bekannt und sollten gegen solche ersetzt werden, die geheimgehalten werden. Dies kann z.B. geschehen, in dem man die entsprechenden Variablen in vars/main.yml oder host_vars/hostname neu definiert. Es bietet sich an, diese zusätzlich mit Ansible-Vault zu verschlüsseln.
Die Tasks in tasks/main.yml
Im vorstehenden Abschnitt wurden die Variablen definiert, welche für die nun folgenden Tasks benötigt werden. Diese sind in tasks/main.yml definiert und werden im folgenden wieder abschnittsweise erläutert.
1 ---
2 # tasks file for ansible_role_deploy_nextcloud_with_mariadb_pod
3 - name: Main folder, needed for updating
4 containers.podman.podman_volume:
5 state: present
6 name: "{{ NC_HTML }}"
7 recreate: no
8 debug: no
9
10 - name: Volume for installed/modified apps
11 containers.podman.podman_volume:
12 state: present
13 name: "{{ NC_APPS }}"
14 recreate: no
15 debug: no
16
17 - name: Volume for local configuration
18 containers.podman.podman_volume:
19 state: present
20 name: "{{ NC_CONFIG }}"
21 recreate: no
22 debug: no
23
24 - name: Volume for the actual data of Nextcloud
25 containers.podman.podman_volume:
26 state: present
27 name: "{{ NC_DATA }}"
28 recreate: no
29 debug: no
30
31 - name: Volume for the MySQL data files
32 containers.podman.podman_volume:
33 state: present
34 name: "{{ MYSQL_DATA }}"
35 recreate: no
36 debug: no
Die ersten Zeilen enthalten Tasks, durch welche die Podman-Volumes zur persistenten Datenspeicherung auf dem Zielsystem erstellt werden. Diese Tasks sind, wie für Ansible üblich, deklarativ und idempotent. Existiert ein Volume bereits, liefert der entsprechende Task ein ‚OK‘ zurück, da keine Aktionen erforderlich sind.
Die folgenden Zeilen erstellen den Podman-Pod und fügen ihm einen Nextcloud- sowie einen MariaDB-Container hinzu. Die Dokumentation der verwendeten Module findet sich in Punkt 5 und 6 im Abschnitt Quellen und weiterführende Links.
In Zeile 64-66 habe ich einen Task definiert, der einfach nur 20 Sekunden wartet. Dies wurde erforderlich, da ich Laufzeitprobleme feststellen konnte, wenn der Nextcloud-Container startet, bevor die Datenbank im MariaDB-Container initialisiert war. Dieses Konstrukt ist nicht schön und ich bin für Verbesserungsvorschläge offen.
Zwischenfazit
Die Erstellung der Ansible-Rolle hat länger gedauert, als angenommen. Dies liegt nur zum Teil in meiner spärlichen Freizeit begründet. Einen größeren Einfluss darauf hatte die Dokumentation zum Nextcloud-Repository. Diese geht davon aus, dass man ein Dockerfile bzw. Docker-Compose verwendet. So war noch etwas Internet-Recherche erforderlich, um den Pod letztendlich ans Laufen zu bringen.
Dieser Artikel beschäftigte sich mit den Tag-1-Aufgaben, an deren Ende eine Nextcloud-Instanz ausgebracht wurde, welche an einen Reverse-Proxy angebunden werden kann.
Im nächsten Artikel gehe ich auf die Konfiguration des NGINX-Reverse-Proxy ein. Hierbei habe ich einige Überraschungen erlebt, welche mich an der Reife des Projekts [2] zweifeln lassen.
Mozilla bereitet den Start seines nächsten Premium-Angebotes vor. Dieses richtet sich vor allem an Webentwickler. Der Start soll bereits im März sein, auch im deutschsprachigen Raum.
Mozilla ist vor allem für seine kostenlosen Produkte wie den Browser Firefox bekannt. Um den Nutzern zusätzliche Mehrwerte zu bieten, aber auch um die finanzielle Abhängigkeit von Suchmaschinen-Anbietern zu reduzieren, setzt Mozilla vermehrt auch auf kostenpflichtige Premium-Angebote wie das Mozilla VPN oder Firefox Relay Premium. Mozillas nächstes Premium-Angebot richtet sich in erster Linie an Webentwickler.
MDN Plus – Entwickler-Dokumentation mit Zusätzen
Die kostenfreie Entwickler-Dokumentation MDN Web Docs, ehemals Mozilla Developer Network, dürfte vermutlich jedem bekannt sein, der bereits mit dem Thema Webentwicklung in Berührung kam. Immerhin ist dies wohl für viele die Anlaufstelle Nummer Eins, wenn es um Themen wie HTML, CSS und JavaScript geht. Und um das direkt klarzustellen: Die MDN Web Docs werden weiterhin kostenlos bleiben. Allerdings wird Mozilla mit MDN Plus ein kostenpflichtiges Zusatzangebot schaffen.
Das Angebot selbst dürfte nicht jeden überraschen, immerhin testete Mozilla bereits im vergangenen Sommer eine Frühversion von MDN Plus. Das Versprechen: Monatliche Artikel mit besonderem Tiefgang zu bestimmten Themen von Branchen-Experten sowie Features, um mehr für sich persönlich aus den MDN Web Docs herauszuholen. Bereits mit Ende des Experiments kündigte Mozilla an, dass man an einem offiziellen Launch arbeiten wird.
Das wissen wir bereits über MDN Plus
Wie meine Recherchen ergeben haben, steht der offizielle Launch von MDN Plus unmittelbar bevor. Bereits ab dem 9. März 2022 dürfte es soweit sein. Zu den Start-Ländern gehören neben Deutschland, Österreich und der Schweiz auch die USA, Kanada, das Vereinigte Königreich, Frankreich, Italien, Spanien, Belgien, die Niederlande, Irland, Malaysia, Neuseeland sowie Singapur.
Neben den bereits erwähnten zusätzlichen Inhalten soll es mehrere Features für Plus-Nutzer geben. Dazu zählt die Möglichkeit, die MDN Web Docs offline nutzen zu können, sich seine persönliche Sammlung anlegen zu können, auf die man von jedem Gerät aus zugreifen kann, sich über Änderungen bestimmter Artikel benachrichten lassen zu können, sowie Themes, um die Plattform ein Stück weit dem eigenen Geschmack anpassen zu können. Wobei nicht unerwähnt bleiben soll, dass man mit seinem Beitrag nicht nur diese zusätzlichen Inhalte und Features bezahlt, sondern eben auch die MDN Web Docs als Plattform damit unterstützt, die von Mozilla seit über 16 Jahren kostenlos bereitgestellt wird.
Der Preis soll nach meinen Informationen bei 10 USD pro Monat respektive 100 USD pro Jahr liegen. Bei uns dürfte die gleichen Zahlen dann vermutlich als Euro-Preise gelten, wenn man von Mozillas bisherigen Premium-Produkten ausgeht.
Ubuntu 22.04 wirft seine Schatten voraus und die Derivate folgen. Nun nehmen auf die elementary-Entwickler Version 7 in den Blick, das auf Ubuntu 22.04 aufsetzen wird. Ein paar Gedanken dazu.
Bekanntermaßen finde ich die Pantheon Shell eine wirklich tolle Desktopumgebung und das insbesondere seit mit Fedora, Arch Linux und openSUSE (OBS) auch andere Distributionen diese ausliefern. Es ist ganz erstaunlich, was da aus kleinen Anfängen gewachsen ist und im Gegensatz zu anderen GNOME-Sprösslingen haben die Entwickler sich hier gleichermaßen emanzipiert, wie auch ein augenscheinlich gutes Verhältnis zu GNOME bewahrt. Deutlich kritischer ist meine Sicht auf die Distribution elementary OS. Momentan fahre ich noch ein Experiment mit elementary OS 6 und Flatpaks, dessen Ausgang weiterhin offen ist.
In ihren monatlichen Berichten haben die elementary-Entwickler Ende Januar die Verlagerung des Fokus auf elementary OS 7 angekündigt. Das ist einerseits nachvollziehbar, weil man vermutlich eine extrem lange Distanz zwischen Ubuntu-Release und elementary-Release vermeiden möchte. Wir erinnern uns: Beim letzten Mal benötigte man über ein Jahr, um eine neue Version auf neuer Ubuntu-Basis zu veröffentlichen. Andererseits ist Version 6 damit weniger als ein Jahr nach Veröffentlichung schon wieder ein Auslaufmodell. Die Erfahrung lehrt, dass die elementary-Entwickler es nicht hinbekommen, mehrere Stränge parallel zu pflegen. Elementary OS 6 wird somit nur noch die nötigsten Bugfixes erhalten.
Dank der Flatpaks erhalten die Anwender trotzdem noch Updates für die Anwendungen und der Übergang auf die kommende Version dürfte hier weniger steinig sein. Schließlich sind die Flatpaks für Version 6 auch unter Version 7 lauffähig und das App Center bleibt daher gut gefüllt. Vermutlich hat elementary hier früh aus richtige Pferd gesetzt, schließlich will auch Flathub demnächst eine Bezahlfunktion einführen.
Andere Bereiche lassen einen da deutlich mehr zweifeln. Aktuell gibt es keine Upgraderoutine, um von einer elementary-Version auf die Nächte zu aktualisieren. Die Entwickler nehmen diese zwar in den Blick, aber selbst wenn diese – was sie ja nicht versprechen – bis Version 7 kommen sollte, sind Funktionen bei elementary am Anfang selten so ausgereift, dass diese wirklich alltagstauglich sind. Weiterhin verstehe ich nicht, warum man immer noch auf Ubuntu als Basis setzt. Die Sollbruchstellen sind kaum noch zu übersehen. Ubuntu setzt auf Snaps, elementary auf Flatpak. Ubuntu will bei 22.04 noch weitestgehend auf Gtk4-Apps verzichten, elementary möchte vollständig auf Gtk4-Apps wechseln. Man kann sich durchaus fragen, wie lange das noch gut geht.
Licht und Schatten sind wie immer bei elementary ganz nah beieinander.
Allerdings alles der Reihe nach, denn Tooling ist ebenfalls wichtig, und
Hugo kannte ich damals noch nicht. CI/CD nutzten wir auf Arbeit
schon mit GitLab , markdownlint war mir ebenfalls
neu.
Bisher hatte ich meine Website immer nur mit selbst geschriebenen
Bashscripts in einem selbst gehosteten Gitrepo verwaltet. Das Bash nicht
die beste Loesung ist, war mir bewusst, denn Bilder einpflegen
erforderte immer etwas Aufwand und die Laufzeit zum Bauen der Website
mit allen Komponenten war auch eher unschoen. Zudem nicht wirklich
crossplattform und teilweise buggy …
Klar war mir, dass ich immer noch eine statische Website haben wollte,
nur eben mit einem besseren/schnelleren/sauberen “Backend”.
Mein erster Schritt war daher die Suche nach einem geeigneten Generator
und ein bisschen auch die Ueberlegung, was ich ueberhaupt noch
veraendern oder neu einbinden wollte. Laut diesen Listen
gibt es ja so einige Generatoren …
Hugo ist in Go geschrieben und erschien 2013. Ueber Hugo bin ich
oefters schon gestolpert, weil darueber einige Leute in den
Planeten drueber geschrieben hatten.
Wenn ich tatsaechlich doch mal noch mehr will , kann ich
auch einfach ein Text in AsciiDoc erstellen. Bisher war das
allerdings noch nicht notwendig, da ich alles relevante in Markdown
schreiben konnte oder mit Hilfe von Shortcodes .
Markdown ist standardmaessig recht limitiert,
was z.B. den HTML-Tag sub oder sup angeht. Je nach Parser gibt es
aber auch Moeglichkeiten mehr als den Standard zu nutzen. Hugo
nutzt z.B. Goldmark , was CommonMark konform ist, und mit dem
ich auch Tabellen und Checklisten generieren kann. Fussnoten und
Durchgestrichenes sind auch drin.
Da nur die Endung (md vs adoc) letztendlich den Unterschied ausmacht
(Front Matter bleibt gleich), bleibe ich erstmal bei Markdown.
Umwandeln kann ich ja Markdown in AsciiDoc mit z.B. Pandoc recht
schnell.
“YAML Ain’t Markup Language” nutze ich schon recht haeufig auf Arbeit
(z.B. docker-compose.yaml oder Kubernetes), daher bin ich damit
schon vertraut.
Ausser JSON ist mir die Nutzung recht egal, und so habe ich mich fuer
YAML im Front Matter entschieden (weil --- schoener aussieht und
leichter zu tippen ist als +++) und fuer TOML in meinen Hugo
Konfigurationsdateien .
Mit “Cascading Style Sheets” (CSS ) wird eine Website erst so richtig
bunt und attraktiv. Allerdings gibt es nicht nur das reine CSS, sondern
auch Varianten, die u.a. Variablen und Funktionen nutzen und dann in CSS
umgewandelt werden koennen.
“Leaner Style Sheets” gibt es seit 2009 und ich hatte schon zumindest
mal davon gehoert. Ein Vorteil von Less ist, dass es eine Obermenge
von CSS ist, d.h. CSS-Code ist gleichzeitig auch gueltiger Less-Code.
“Syntactically awesome style sheets” gibt es seit 2007 und war mir
auch schon gelaeufig. Neben Sass gibt es auch noch “Sassy CSS” (SCSS),
welches statt Einrueckungen die CSS Formatierung nutzt.
Stylus kannte ich vorher noch nicht, gibt es aber schon seit 2010.
Statt der Nutzung von geschweiften Klammern wird hier auf Einrueckung
gesetzt, Zeichen wie :, ; und , sind optional und koennen
weggelassen werden.
Die Entscheidung zur Nutzung von SCSS fiel mir nicht schwer, da Hugo
schon Support fuer Sass/SCSS mitbringt, was bei
Less/Stylus (noch?) nicht der Fall ist .
Zudem finde ich die Nutzung von geschweiften Klammern wie bei CSS
ueblich schoener als Einrueckungen 😉
Irgendwo muss die Website ja auch laufen. Bisher teilte ich mir einen
Server bei Hetzner mit Flo .
Allerdings wollte ich mir mal einen eigenen Server (VPS reicht)
goennen und auch dort moeglichst viel nach dem Prinzip von
Infrastructure as code (IaC) umsetzen.
Zudem sollte nicht nur die Website dort laufen, sondern u.a. auch Git,
Seafile , newsboat , weechat , neomutt , …
Und natuerlich alles unter Arch Linux mit root-Zugriff. Daher
fielen direkt schonmal einige Hostingideen raus, die ich hier aber
trotzdem mal aufliste:
Ist zwar bestimmt spannend zu nutzen um mal tiefer in das Thema
Kubernetes einzusteigen, aber etwas Overkill fuer meine kleine
Website. Fuer AWS gibt es Arch Linux Images .
Kein root, kein Arch Linux, kein ssh. Aber generell sinnvoll fuer
Menschen, die nur ihre Website online bringen wollen. Auch
erwaehenswert: Netlify CMS und Front Matter
Kurz: ich habe mich fuer Netcup entschieden, einfach weil ich mit
denen schon gute Erfahrungen beruflich (und auch vor Jahren privat)
gesammelt habe und sie Arch Linux schon als ISO anbieten 😉
Zudem ist die Verwaltung der Server (inkl. Umzuege) sehr einfach.
Mit der Klaerung des Hostings stellte sich mir die Frage, wie ich auch
das System dahinter moeglichst gut via IaC abbilden kann.
Bisher (berufliche) Erfahrung gesammelt habe ich mit:
Das ist allerdings wesentlich komplexer, fuer mich alleine und mein
kleines VPS. Im Zusammenhang mit Arch Linux bin ich dann noch auf
folgende Moeglichkeiten gestossen:
Klingt erstmal sehr gut, auch die Beschreibung im
README und der Vergleich zu Puppet, Ansible,
NixOS usw.
Tatsaechlich bin ich erst spaeter darauf gestossen, als ich schon eine
Loesung hatte 😉
Ein sehr interessanter Ansatz, einfach ein ISO zu erstellen und bei
Netcup hochzuladen. Allerdings waere das ISO dann erstmal nur auf den
Server zugeschnitten. Aenderungen sind natuerlich nachtraeglich
machbar, ohne nochmal den ganzen Server aufzusetzen. Trotzdem,
irgendwie aufwaendig.
Sehr coole Moeglichkeit, mehrere Maschinen einfach mit den vorhandenen
Boardwerkzeugen bzw. also Textdateien aufzusetzen. Darauf gekommen
bin ich durch diesen Blogeintrag .
Letztendlich entschieden habe ich mich fuer meta packages, da sie
einfach zu erstellen und warten, und auch mit CI/CD ausspielbar
sind.
Ein Beitrag ueber die Suche und die Technik dahinter sind in Arbeit.
Die Grundlage von CI /CD ist Versionsverwaltung (bei mir
Git ), klar. Aber wie bekomme ich den Code jetzt gebaut und auf den
Server? Hierbei habe ich mir folgende Loesungen angeschaut:
GitHub Actions wurden 2019 eingefuehrt und fand ich
natuerlich direkt spannend. Irgendwann habe ich es dann auch mal fuer
ein paar Repos eingebunden und fuer gut befunden.
GitLab gibt es seit 2014 und waberte immer mal wieder durch die
Blogosphaere. Seit wann CI/CD integriert ist, konnte ich nicht
herausfinden. Jedenfalls nutze ich GitLab CI seit Jahren beruflich.
Travis gibt es seit 2011. Ich bin immer wieder in diversen Repos
darueber gestolpert und habe es dann selbst kurz ausprobiert, bevor
GitHub Actions rauskam.
Mein Code fuer die Website liegt aktuell bei GitHub, daher nutze ich
auch die GitHub Actions fuer das Testing und Deployment der Website.
GitLab CI waere aber auch eine gute Alternative.
Was wollte ich ueberhaupt mit dem ganzen Umbau? Warum nicht alles so wie
bisher weiterbetreiben nach dem Motto never change a running
system ?
Ich war schon sehr lange nicht mehr zufrieden mit meiner Loesung, aber
es hat erstmal funktioniert. Doch mit dem Anreiz, mal alles neu zu
machen, habe ich mir eine Liste zusammengestellt bzw. mal einfach drauf
los rumgewerkelt.
Hier also eine Liste mit Dingen, die ich mit dem neuen statischen
Generator (also Hugo) umsetzen wollte bzw. will. Einige Dinge habe ich
noch nicht umgesetzt oder bin noch dabei, daher die Checkboxen.
Alles muss textbasiert sein
Also so wie auch vorher schon und damit auch fuer Git geeignet -
abgesehen natuerlich von Bildern etc.
Wobei der letzte Befehl nicht ganz richtig ist, erst habe ich eins der
vielen Themes kopiert (XMin ) und nach und
nach durch eigenen Code ersetzt, wobei ich mich erstmal an dem Stil der
alten Version orientiert habe.
Die alte 'Über mich'-Seite in Version 11.7
Im Prinzip habe ich nach und nach jede Datei angepasst, sei es wegen
Markdown-Anpassungen (Codebloecke z.B.), Emojis,
Aktualisierungen/Ergaenzungen/Streichungen; das Hinzufuegen/Anpassen von
Templates oder den Einbau von Shortcodes
(Bilder z.B.).
Beim Wechsel zu Hugo wollte ich so wenig wie moeglich an der alten
Struktur veraendern. Und wenn doch, moeglichst alles umleiten, damit
alte Links immer noch ans Ziel kommen.
title:"Sinn des Lebens"date:2007-05-27T13:10:31+02:00draft:falsetags:["tv","sinn","leben"]aliases:["/1180264231.htm"]# magic
Beim Bauen von Hugo wird nun ein Ordner 1180264231.htm mit der Datei
index.html angelegt, die ein meta http-equiv="refresh" zu der neuen
Location beinhaltet. Das ist auch schon die ganze Magie dahinter. Laut
Hugo habe ich so ca. 288 Aliase in meinen Dateien … 🙈
Fuer den Rest habe ich folgendes in meiner nginx Config:
Diese sorgen fuer die notwendigen Weiterleitungen, gerade fuer die
Feeds in den Planeten.
Das Einzige, was ich leider nicht weiterleiten konnte, sind die
einzelnen Linkdumps, das waren naemlich einfach nur Anker zu einer
jaehrlichen Uebersichtsseite …
Eine Uebersicht der Linkdumps in 2012 mit Ankern in Version 11.7
Zumindest wird linkdump_2012.htm weitergeleitet zur jetzigen
Uebersichtsseite … Naja, es gibt schlimmeres 😉
Es sollte eigtl. Standard sein, dass alle JavaScript- und CSS-Dateien
gebuendelt und “minifiziert ” werden, bevor
sie ausgespielt werden. Zudem sollte auch HTML “gecrunched” werden. All
das ist moeglich mit Hugo Pipes 🎉
Mein Ziel war es, ein simples, aber ansprechendes Layout hinzubekommen,
und nicht so weit entfernt vom alten Design. Inspirationen gibt es ja
alleine mit den Hugo Themes genug, aber ganz cool fand
ich die Iterationen der Motherfucking Website
(Suche , Reddit ):
Zusaetzlich zur Farbpalette (was eine Wisschenschaft fuer sich ist)
kommen dann noch “Feinheiten” wie “neue” HTML-Tags ,
typographische Elemente wie Smart Quotes , und sonstige
schoene Elemente. Davon hat die Designwelt ja recht viel 🤓
Am Ende habe ich einfach das Standard-CSS in etwas
abgewandelter Form verwendet.
Die Farben sind bei mir jetzt also Weiss(-isch) als
Hintergrundfarbe (#fafafa), Schwarz(-isch) als
Schriftfarbe (#27272a), Gruen(-isch) als Linkfarbe (#04815D). Ich habe nur kein Lila als “Visited”
verwendet, aber Underline als
“Hover” .
Wichtig waren mir dabei Farben, die die folgenden Kontrasttests bestehen
(und ich hab mir mal eben schnell noch neue
Shortcodes gebaut 😉):
Das schwierigste (zumindest fuer mich) ist ein sauberes (S)CSS. Zudem
habe ich ja mehrere Fremdsysteme mit aufgenommen (z.B. Lightbox und Font
Awesome), die ja auch noch (S)CSS mitbringen. Das alles unter einen Hut
zu bringen ist nicht immer ganz einfach, aber nur so lerne ich auch dazu
😉
Etwas aufgehalten hat mich auch der selbst gebastelte,
datenschutzfreundliche Gist-Shortcode, denn der passt nicht mit
meinen anderen Styles (besonders pre und code) zusammen. Allerdings
koennen Dinge ja ueberschrieben werden 😉
Zur Vorbereitung auf den Dark Mode habe ich noch etwas
anpassen bzw. hinzufuegen muessen. Und zwar habe ich erst in
config/_default/markup.toml die Parameter zu
Highlight wie folgt gesetzt:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
[highlight]anchorLineNos=falsecodeFences=trueguessSyntax=falsehl_Lines=''hl_inline=falselinkAnchors=''lineNoStart=1lineNos=falselineNumbersInTable=truenoClasses=false# wichtig ist diese Anpassung auf falsenoHl=falsestyle='solarized-light'tabWidth=2
Mit dieser Einstellung muss ich die entsprechenden Klassen nun selbst
hinzufuegen (damit kann ich sie aber z.B. spaeter fuer den Dark
Mode einfach ueberschreiben). Ich habe mich fuer den Style
solarized-light entschieden, eine Uebersicht gibt es in der Chroma
Style Gallery . Die entsprechenden Klassen kann ich mit
dem folgenden Befehl an meine assets/css/style.scss anhaengen:
hugo gen chromastyles --style 'solarized-light' >>assets/css/style.scss
Eine dunkle Variante hatte ich sogar schon eingebaut, allerdings bin ich
mit dem (S)CSS noch nicht zufrieden gewesen. Das kommt also noch
😉
Update (2024-07-07):
Ok, das hat etwas gebraucht. Und fertig bin ich immer noch nicht
😅
Aber hey, eine erste Iteration ist da!
Ich hatte in meinen Notizen schon sehr viele (ok, nach Ausduennung
dann doch nicht mehr so viele) Informationen bzw. Inspirationen (z.B.
Hugo Themes mit dem Tag “dark mode” ) zu diesem Thema
gesammelt, aber es kommt ja dann doch irgendwie immer ganz anders.
Update (2025-10-20):
Hier war mal eine komplizierte Anleitung, wie Tailwind zu integrieren
ist, aber es gibt das jetzt einfach in der offiziellen Doku, naemlich
css.TailwindCSS .
Damit habe ich meine CSS Dateien auch ausgelagert:
Und dann eben wie beschrieben in der layouts/baseof.html eingebunden.
In der CSS Datei habe ich dabei
Einige Einstellungen habe ich dann in der assets/css/tailwind.css
gesetzt, z.B. habe ich die preflight-Zeile Preflight
rausgenommen , damit ich nicht alle Standard-Tags
nochmal neu stylen muss.
Das sind hauptsaechlich Tags, die ich so nicht einfach setzen kann, weil
sie via Markdown einfach generiert werden (z.B. blockquote und
code). Zudem habe ich dort auf alle img-Tags im Dark Modus einen
Filter angewendet (siehe Dark Mode Images ), damit
die Bilder nicht so hell sind im Vergleich.
Tja, und dann kann die Nutzung losgehen. Ich habe einfach mal mit der
layouts/baseof.html angefangen (mit dem ) und quasi
alles aus der SCSS in Tailwind CSS uebersetzt. Geholfen haben mir da
sehr diese zwei Converter: SCSS to CSS und CSS to
Tailwind CSS .
Und bin dann nach und nach alle Shortcodes etc. durchgegangen. Die
meisten Probleme hatte ich mit der Syntaxhervorhebung. Dazu habe ich
erstmal eine weitere Variante (naemlich solarized-dark) zu meiner
assets/css/style.scss hinzugefuegt:
hugo gen chromastyles --style 'solarized-dark' >>assets/css/style.scss
Aber seit der letzten Generierung vor ein paar Jahren hat sich die
Software dahinter weiterentwickelt und meine kompletten Codekaesten
zerschossen. Nach langem Probieren und Rumsuchen bin ich dann dank des
Hugo Entwicklers Joe Mooring auf ein paar Zeilen
Loesung (noch mehr dazu von
ihm ) gestossen (danke dafuer!):
Und damit ist nun fast alles in die Shortcodes usw. gewandert, aber eben
auch ein paar Sachen in assets/css/tailwind.css bzw. noch in
assets/css/style.scss geblieben (zumindest den Chroma Kram wuerde ich
auch dort drin lassen).
Eine coole Sache noch, die mir via diesem Guide aufgefallen
ist:
<metaname="color-scheme"content="dark light">
Das im Header (also in layouts/baseof.html) sorgt dafuer,
dass Formularfelder wie bei meiner Suche auch entsprechend dem
Dark oder Light Mode eingefaerbt werden. The more you know 😉
Mit Tailwind CSS hatte ich die Gelegenheit, von Grund auf direkt damit
zu starten , habe diese aber nicht genutzt. Also
steht das noch auf meiner TODO Liste.
Ich habe lange herumprobiert und mich dann letztendlich dazu
entschieden, nur die Woff2-Dateien durch etwas CSS einzubinden. Also
kein JavaScript und auch keine SVG Sprites.
Zwar kann IE damit nicht umgehen , aber … who cares? 😉
Die Nutzung erfolgt entweder direkt (also mit HTML Code) oder via
Shortcode . Ich habe dazu einfach selbst einen
gebastelt (layouts/_shortcodes/icon.html):
Genutzt werden kann es nun z.B. auf einer Seite content/test.md wie
folgt:
{{<iconsize="fa-lg"anim="fa-spin"col="#abcdef">}}
Info
Der obige Code musste auskommentiert werden, damit er nicht ausgefuehrt
wird. Das geht, indem nach dem < ein /* und vor dem > ein */
hinzugefuegt wird.
Dieser Code erzeugt dann das hier: .
Wichtig ist hierbei, dass die Datei keine neue Zeile am Ende enthaelt,
denn sonst wird das Icon mit einem Leerzeichen
dahinter dargestellt.
Sofern eine .editorconfig genutzt wird, kann folgendes
fuer .html-Dateien hinzugefuegt werden:
[*.html]
insert_final_newline = false
Alternativ kann das Leerzeichen laut Stackexchange mit perl -pi -e 'chomp if eof' /path/to/file entfernt werden.
Die Bilder wollte ich wie bisher auch mit einem
Polaroid-Effekt versehen (zudem Lightbox zum schoener
darstellen und navigieren), diesmal aber via CSS, statt vorgeneriert mit
convert.
Polaroid Bilder in der alten Version 11.7
Inspirationen fuer die Umsetzung habe ich ein paar gefunden und damit folgenden SCSS-Code in
assets/css/style.scss gebastelt:
Bisher habe ich vorwiegend Bilder in den Formaten JPEG und PNG
verwendet. Allerdings gibt es seit Version v.83.0 in Hugo
Support fuer WebP , was laut Can I use… in den meisten
derzeit genutzten Browsern verwendet werden kann.
Ein paar der bisher genutzten Bilder habe ich nachtraeglich mit
cwebp (alternativ convert) umgewandelt. Dank
Hugo kann ich aber zumindest die Thumbnails automatisch mit einem
Shortcode umwandeln lassen 🎉
Ich glaube, der Shortcode fuer Bilder ist eins
der am haeufigsten angepassten Shortcodes, ein Beispiel gibt es im
Forum . Mein Shortcode ist auch angepasst und hat
Lightbox-Code schon integriert, zudem noch ein paar andere Dinge wie
Unterschriften, Qualitaet, Linkziele, Format, …
Auf meiner TODO-Liste steht noch lazy loading , was aber
etwas komplexer ist.
Ein Favicon hatte ich ja vorher schon, nur die
Einbindung war noch nicht ganz perfekt. Ueber die Website
RealFaviconGenerator habe fuer ca. alle Plattformen das richtige
Bild erstellen und in layouts/baseof.html einbinden koennen:
Mein SCSS in assets/css/style.scss im Folgenden enthaelt Mixins (quasi
Funktionen) und Variablen, da ich es z.B. auch fuer Twitter
in aehnlicher Form verwendet habe:
Das Feature Render Hooks gibt es seit Version
v0.62.0 und erlaubt es, bei Headern (also z.B. ) den
Permalink daneben hinzuzufuegen (bei mir durch ein # gekennzeichnet)
oder Links zu anderen Websites mit einem Icon (bei mir ) kenntlich zu machen.
Der Code in layouts/_markup/render-heading.html fuer die
Header sieht so aus:
Durch die Abfrage mit dem Prefix http werden nur externe Links mit dem
Icon versehen, interne Links sind relativ und werden daher nicht mit gekennzeichnet.
Verlinke ich jetzt einen RSS-Feed, erscheint das Icon: Link zu einem
RSS-Feed. Das funktioniert auch mit externen Feeds, dann
wird zusaetzlich noch der render-link.html angehaengt: Link zu
externem “RSS-Feed” .
Update (2024-01-28):
Eine Integration von \(\LaTeX\) wollte ich schon seit langer
Zeit haben (einfach weil ich es kann, schoen und einfach finde (git !),
damit meine Bachelor Arbeit erstellt habe und immer noch zum
Briefe schreiben nutze) und hatte dazu auch schon mehrere
Vorgehensweisen entdeckt:
Better TeX math typesetting in Hugo (mit KaTeX ,
beruft sich auf ein nicht mehr existierendes Hugo Tutorial und macht
den Case “LaTeX in RSS” auf, was ich allerdings erstmal™ auslasse)
Zuerst habe ich meine markup.toml und params.toml um die jeweiligen
Konfigurationen ergaenzt, allerdings ist der Default fuer math bei
mir auf false gesetzt (muss dann also im Frontmatter auf true
gesetzt werden, wenn LaTeX aktiviert sein soll). Zudem habe ich nur
jeweils eine Konfiguration fuer “block” und “inline”, da ich die eine
“block”-Syntax auch in einem anderen Kontext nutze:
Allen Anleitungen gemein ist die blinde Einbindung von JavaScript
ueber ein Content Delivery Network . Da ich das aus
Datenschutzgruenden nicht nutzen will, werde ich auch hier die
benoetigten Dateien via npm und Hugo Mounts
einbinden.
Zu guter Letzt werden die beiden Dateien moeglichst umstaendlich™ in
layouts/baseof.html im eingebunden, analog zu den
anderen JavaScript-Dateien (ich habe hier noch keine bessere
Moeglichkeit gefunden, abhaengig von der Konfiguration im Frontmatter
unterschiedliche JavaScript Dateien usw. einzubinden, daher wird es nun
als weiteres Bundle nur nachgeladen, wenn der Parameter math gesetzt
ist):
Und damit kann ich jetzt endlich \(\LaTeX\) nutzen, woop woop (an das
math: true im Frontmatter denken) 🎉
So zum Beispiel den Satz vom Igel , an den ich mich noch
aus meinem Studium erinnern kann:
Für jedes \(m\in \mathbb {N}\) und für jede stetige Abbildung \(f\colon
\mathbb {S} ^{2m}\to \mathbb {R} ^{2m+1}\) existiert ein \(x_{0}\in
\mathbb {S} ^{2m}\) und ein \(\lambda \in \mathbb {R}\) mit
\(f(x_{0})=\lambda \cdot x_{0}\).
Der Code in der Doku reicht leider nicht fuer meine
Beduerfnisse, denn ich will eigentlich immer ein Inhaltsverzeichnis
haben, wenn der Text 400 oder mehr Woerter enthaelt und nicht der Flag
toc: false gesetzt ist.
Ansonsten soll das Inhaltsverzeichnis nur angezeigt werden, wenn es 2
oder mehr Header gibt (egal welche).
Mein Code in _partials/block/toc.html sieht daher wie folgt aus (mit
Nutzung von ):
Soll eine Seite/Beitrag oder was auch immer nicht in der Sitemap
erscheinen, kann die Loesung von Fryboyter verwendet
werden. Eine Alternative Loesung bei Mert Bakır . Meine
Loesung in layouts/sitemap.xml sieht jetzt einfach so aus:
Natuerlich laesst sich die robots.txtauch anpassen .
Ein Forumsbeitrag enthaelt z.B. die Moeglichkeit,
einzelne Seiten/Beitraege nicht zu erlauben (aehnlich zur
Sitemap). Meine sieht z.B. so aus (layouts/robots.txt),
indem ich einach den gleichen Parameter wie bei der Sitemap
nutze:
#https://github.com/ai-robots-txt/ai.robots.txt{{-$url:="https://raw.githubusercontent.com/ai-robots-txt/ai.robots.txt/refs/heads/main/robots.txt"-}}{{-withtry(resources.GetRemote$url)-}}{{-with.Err-}}{{-errorf"%s".-}}{{-elsewith.Value}}{{.Content-}}{{-else-}}{{-errorf"Unable to get remote resource %q"$url-}}{{-end-}}{{-end}}#https://en.wikipedia.org/wiki/Robots.txtUser-agent:*{{rangewhere.Data.Pages"Params.exclude"true-}}Disallow:{{.RelPermalink}}{{end}}#https://en.wikipedia.org/wiki/Robots.txt#SitemapSitemap:{{"sitemap.xml"|absLangURL}}
Wichtig bei einer eigenen robots.txt ist folgende Einstellung in
config/_default/config.toml:
Normalerweise sehen die Errorcodes-Seiten ziemlich langweilig aus. Mit
Hugo ist es moeglich, diese auch wie eine normale Webseite
auszugeben und mit z.B. nginx zu nutzen
(content/403/index.md):
Wichtig ist hier die Zeile mit url: 403.html, denn ansonsten wuerde
Hugo dies als /403/ ausgeben, womit nginx Schwierigkeiten hat, daher
reicht nun einfach:
Da ich in mehreren Planeten gelistet bin, brauche ich
natuerlich auch einen ordentlichen RSS-Feed , wenn nicht sogar
mehrere 😉
Allerdings ist das Default-Template nicht ausreichend genug,
denn ich will im Feed nicht nur ein Summary eines Beitrags drin haben,
sondern eben den ganzen Beitrag . Zudem sollen nicht alle
Beitraege im Feed sein, sondern nur die neuesten 10, was mit
einem limit = 10 gesetzt werden kann.
Allerdings soll die Tags-Seite kein RSS ausspucken (wozu auch?). Dazu
ist eine Anpassung der Outputs in
config/_default/outputs.toml notwendig:
page=["html"]home=["html","rss","manifest"]section=["html","rss"]# taxonomy soll kein rss beinhaltentaxonomy=["html"]term=["html","rss"]
Hugo wirft jetzt erstmal einen Fehler bei dieser Aenderung aus:
ERROR 2021/12/13 17:12:50 You have configured output formats for 'taxonomy' in your site configuration. In Hugo 0.73.0 we fixed these to be what most people expect (taxonomy and term).
But this also means that your site configuration may not do what you expect. If it is correct, you can suppress this message by following the instructions below.
If you feel that this should not be logged as an ERROR, you can ignore it by adding this to your site config:
ignoreErrors = ["error-output-taxonomy"]
Da ich mir sicher bin, dass ich kein RSS-Feed fuer meine Tags-Seite
haben will, kann ich den Fehler in der config/_default/config.toml
ignorieren:
ignoreErrors=["error-output-taxonomy"]
Falls ihr nicht sicher seid, was alles noch einen RSS-Feed ausspuckt,
und ob das wirklich notwendig ist, koennt ihr eure Seite erstmal bauen
und dann nach rss.xml suchen. Bei mir hatten sich ein paar Dateien
eingeschlichen, die durch Sektionen generiert wurden, obwohl das gar
keine Section sein muss. Also mal schnell ein git mv _index.md index.md gemacht in den entsprechenden Ordnern und bis auf eine Sektion
war alles gut (steht noch auf meiner TODO-Liste das zu fixen) 😉
Update (2024-04-05)
Das ist mittlerweile gefixt, indem ich
einfach im Frontmatter outputs ueberschreibe (und rss einfach
weglasse):
Auch das wollte ich schon immer mal haben, eine einfache Navigation zum
vorherigen bzw. naechsten Beitrag oder Rezept. Und auch das ist mit Hugo
recht einfach moeglich:
Hierzu nutzen wir einfach die Variablen , die Hugo uns
fuer eine Seite zur Verfuegung stellt. Meine Datei
layouts/_partials/page/prev_next.html, die z.B. in
layouts/block/single.html eingebunden wird, sieht so aus (unter
Nutzung von Icons):
Wie in der alten Version, generiert durch ein paar Bashskripte, wollte
ich wieder eine Tagcloud . Das ist natuerlich auch mit Hugo
moeglich (Taxonomy als Stichwort ).
Diesmal allerdings nicht direkt nativ, d.h. ich habe mir den Code von
verschiedenen Quellen angeguckt und schliesslich von Artem Sidorenko
uebernommen . Danke!
Die Seite an sich ist die Uebersichtsseite der Tags, die via
layouts/tags/list.html modifiziert werden kann. Dort habe ich
einfach ein Partial namens layouts/_partials/term_cloud.html angelegt
mit folgendem Inhalt:
Update (2024-07-07):
Da ich letztens ueber Kategorien vs
Schlagwörter gestolpert bin: Ich habe den Einsatz von
Kategorien in Hugo noch nie verstanden und habe
deshalb auch keine im Einsatz. Tags reichen mir vollkommen aus.
Dank Hugo ist das sehr einfach moeglich. Generell nutze ich nun keine
Endung (genannt Ugly URLs ) mehr bei den
Eintraegen/Seiten (also z.B. kein $timestamp.htm bei den
Blockeintraegen), was in Hugo der Default ist. Allerdings
sollten die Blockposts anders dargestellt werden. Das geht in der
Config so :
Update (2022-08-06):
Seit Jahren habe ich mich auf externe Suchmaschinen verlassen,
wollte aber schon immer eine “eigene” Suche haben. Ich hatte auch schon
des oefteren angefangen zu recherchieren, was ich denn nun eigentlich
einsetzen will, habe mich aber nicht zu einer Loesung durchringen
koennen. Im Raum standen z.B. eine Suche mit Lunr oder mit
einem JSON Feed .
Der Nachteil dabei wurde in den letzten
Tagen auf Brain Baking beschrieben (dieser Feed oder
Index kann je nach Umfang der Website dann natuerlich auch selbst sehr
gross sein und muss komplett client-seitig heruntergeladen werden).
Und daher setze ich nun, wie auch viele andere in den letzten Wochen auf
das noch recht junge Projekt Pagefind , was die Suche auf allen
Seiten vereinfacht, da hier mit Fragmenten gearbeitet wird und der Index
erstellt wird, nachdem die Website gebaut wurde 😊
Der Einbau war sehr einfach, ich habe einfach ein Partial
layouts/_partials/search-pagefind.html erstellt und es auf einer Seite
eingebunden:
Update (2024-04-02):
Ein lang ersehntes Feature war der Autofocus
in der Suchleiste (siehe Issue dazu ), was ich nun dank
Pagefind v1.1.0 auch endlich einbauen konnte.
Dabei wurden nicht nur Eintraege, Linkdumps,
Rezepte usw. gezaehlt, sondern auch die Haeufigkeit von
Suchmaschineneingaben (ausgelesen ueber die Webserverlogs). Das
funktioniert mit der Nutzung von GitHub Actions jetzt nicht mehr so
einfach (auch die vorherigen Zaehlungen koennen mit Hugo nur schwierig
abgebildet werden).
Daher halt eben nur eine kleinere Statistik. 😊
Allerdings wuerde ich gerne noch ein paar kleine Dinge mit einbauen:
die Hugo Statistik, die beim Bauen angezeigt wird
eine Auflistung aller Dateiendungen sortiert nach der Haeufigkeit
Ersteres laesst sich generieren ueber einen normalen Durchlauf von Hugo,
wobei der Output in eine Datei geschrieben wird.
Zweiteres funktioniert mit einem find-Befehl , der
ebenfalls in eine Datei geschrieben wird.
Beide Dateien werden anschliessend bei einem (zweiten) Durchlauf mit Hilfe
von readfile eingebunden.
# Hugo Statistik$ hugo | grep -v "^INFO"| sed '1d'hugo v0.90.1+extended darwin/amd64 BuildDate=unknown
INFO 2021/12/11 20:14:31 syncing static files to /
| DE
-------------------+-------
Pages |1099 Paginator pages |0 Non-page files |907 Static files |125 Processed images |805 Aliases |287 Sitemaps |1 Cleaned |0Built in 1370 ms
# Auflistung aller Dateiendungen sortiert nach der Haeufigkeit (erstmal nur die letzten 10)$ find . -type f | grep -oE '\.(\w+)$'| sort | uniq -c | sort | tail
26 .woff
26 .woff2
195 .png
272 .xml
278 .js
512 .md
1057 .html
1663 .svg
1786 .webp
2215 .jpg
Beides habe ich noch nicht umgesetzt, das steht noch auf meiner
TODO-Liste.
Update (2024-04-05):
Beides habe ich mittlerweile umgesetzt.
Hierbei kommt das Update v0.124.0 mit Segments zum
Einsatz. Die genauen Befehle sind im GitHub Workflow
ersichtlich. In meiner hugo.toml habe ich lediglich folgendes
definiert:
Bisher habe ich Aenderungen in einer Datei namens changelog.txt
festgehalten, diese wurde nun durch eine regulaere Seite
ersetzt. Zusaetzlich gab es noch eine Datei namens version.txt, die
ist nun aber auch im Changelog aufgegangen.
Lange Zeit hatte ich nur Major- und Minor-Versionen festgehalten, nun
kehre ich wieder zu Semantic Versioning zurueck, also
zusaetzlich mit Patch-Version.
Schoen waere noch ein automatischer Changelog, zusammengebaut via Git
Log und/oder Tags. Aber mal gucken, steht als Low Prio auf meiner
TODO-Liste.
Update (2024-04-05):
Diese Idee habe ich mittlerweile komplett
verworfen, siehe dazu den Eintrag zum Changelog.
Es gibt zwar ein paar Moeglichkeiten, die
Standard-Shortcodes etwas datenschutzfreundlicher zu
gestalten (Bountysource ), allerdings gehen diese mir
nicht weit genug. So wird bei einem Seitenaufruf immer noch Zeugs von
anderen Websites nachgeladen, was ich natuerlich nicht will (und ihr
wohl auch nicht).
Daher habe ich mir die Muehe gemacht, selber was zu basteln.
gist und twitter kommen ohne sonstige Skripte
aus, bei youtube und vimeo ist noch ein Skript
notwendig, was das Thumbnail runterlaedt und auf die passende Groesse
von 560x560 (siehe geometry bei imagemagick)
umwandelt. instagram habe ich bisher nicht gebraucht und
github (als Alternative zu gist) sowie
osm habe ich neu gebaut. spotify wollte ich auch
noch bauen, aber die API ist doof 😉
Die Einbindung von Gists ist mir nicht datensparsam genug
(es werden Sachen von GitHub nachgeladen). Zum Glueck gibt es die
Moeglichkeit, per API u.a. den Code abzufragen. Im Gegensatz
zu dem offiziellen Hugo Shortcode benoetigt mein
Shortcode (layouts/_shortcodes/gist.html) mit “Positional
Parameters” nicht den Namen, sondern nur die Gist ID und
ggf. einen Dateinamen, wenn der Gist mehrere Dateien enthaelt, aber nur
eine angezeigt werden soll:
{"name":"gist-embed","authors":["Blair Vanderhoof"],"description":"Ultra powered gist embedding for your website http://blairvanderhoof.com/gist-embed/","main":"gist-embed.js","keywords":["gist","embed","github","ajax"],"license":"BSD-2-Clause","homepage":"https://github.com/blairvanderhoof/gist-embed","repository":{"type":"git","url":"https://github.com/blairvanderhoof/gist-embed.git"}}
In diesem Shortcode muss die Sprache mit angegeben werden, da die
API diese leider nicht mit ausgibt. Zusaetzlich gibt es
noch die Moeglichkeit, dem Shortcode highlight Optionen
mitzugeben:
#!/usr/bin/env python"""convert a depth map image to a 3d txt map to be used by `aa3d`"""# inspiration:# https://github.com/RameshAditya/asciify/blob/master/asciify.pyimportsystry:fromPILimportImageexceptImportError:print("Unable to import pillow")sys.exit(1)# main# - takes as parameters the image path [width and intensity]# - converts an image to a txt map# - prints result to consoleif__name__=='__main__':# try to load imagetry:image=Image.open(sys.argv[1])exceptIndexError:print("No image given")sys.exit(1)exceptIOError:print("Unable to load image")sys.exit(1)# set width (default: 80), in the range of 1-500try:WIDTH=max(1,min(abs(int(sys.argv[2])),500))except(IndexError,ValueError):WIDTH=80# set layers (default: 9), in the range of 1-9try:LAYERS=max(1,min(abs(int(sys.argv[3])),9))except(IndexError,ValueError):LAYERS=9# resize imageimage.thumbnail((WIDTH,WIDTH))# greyscale (8-bit pixels, black and white) since the input should# be like this anyways (this will also provide just one integer in# the range of 0-255 instead of a tuple)image=image.convert('L')# convert every pixel to a value 0-9 corresponding to their intensitypixels=[list(map(str,range(0,9)))[p//(256//LAYERS)]forpinlist(image.getdata())]# and join the resultPIXELS_RES=''.join(pixels)# construct the image from the character listnew_image=[PIXELS_RES[i:i+WIDTH]foriinrange(0,len(PIXELS_RES),WIDTH)]# and print the resulting linesprint('\n'.join(new_image))
Wobei Disqus aus Datenschutzgruenden natuerlich nicht die beste Wahl
ist. Auf der Seite im Wiki werden aber Alternativen
aufgelistet .
Isso kenne ich schon sehr lange und hatte es probeweise auch
schon im Einsatz, allerdings habe ich es noch nicht mit Docker am
Laufen. Und die Python-Dependency-Hell will ich mir nicht
nativ antun.
tl;dr Kommentare will ich haben, allerdings habe ich mich noch nicht
fuer eine Loesung entschieden, daher ist das noch ein TODO auf meiner
Liste 😉
Statt Google Maps sollte OpenStreetMaps verwendet werden.
Doch wie datenschutzfreundlich einbinden? Denn der Standard Embed-Code
laedt $Dinge direkt von OpenStreetMaps …
Hierbei wird erstmal nur ein Bild mit Text im Vordergrund angezeigt.
Erst bei Klick auf das Icon () in der Mitte
wird die Karte in einem Iframe nachgeladen. Alternativ kann der Link
unter dem
genutzt werden, der direkt auf die
OpenStreetMap-Website verlinkt.
Den Code dafuer habe ich fuer youtube uebernommen aus
einem Beitrag von Florian Meier (Code auf GitLab )
mit einigen Anpassungen und ihn dann fuer OpenStreetMap nochmals
angepasst:
Nutzung von getJSON bzw. der YouTube-API ,
um Informationen ueber das Video zu bekommen und in dem Container
darzustellen (in diesem Fall nicht notwendig) und damit auch Anpassung
des Textes
Info
Laut einem Issue
ist .RenderString besser in solchen Situationen geeignet als
markdownify.
Nutzung eines Scriptes, um das Vorschaubild im Hintergrund
runterzuladen (mehr dazu in vimeo); in diesem Fall wird
ein statisches Bild genutzt, siehe unten
Der notwendige CSS-Code zum Stylen ist dank Tailwind CSS direkt im
Shortcode enthalten.
Und hier noch das Bild, was im Hintergrund angezeigt wird (abgewandelt
vom Original ):
OpenStreetMap Logo
Abgeleitet vom Embed-Code sieht mein Shortcode dann wie folgt aus:
Aehnlich zu osm, vimeo und youtube
habe ich mir auch das einfach selbst gebastelt bzw. es erstmal nur
versucht.
Denn das Problem war: Hugo konnte noch nicht mit
POST-Requests umgehen. Zuerst hatte ich mir daher mit
curl einen Access Token besorgt und den dann mit Hugo genutzt.
Allerdings ist all das jetzt mit resources.GetRemote
(seit Version 0.91.0 ) moeglich 🎉
Dank der kurzen Haltbarkeit des access_tokens von nur einer Stunde ist
die lokale Entwicklung aber sehr nervig. Daher im Folgenden nur ein
Proof of Concept .
Nach etwas Hilfe aus der Community hatte ich dann
auch meinen Shortcode layouts/_shortcodes/spotify.html zusammengebaut:
Diese Datei erlauben wir jetzt mit direnv allow . und koennen danach
Hugo starten:
hugo server -v -D
Nun werden die Variablen genutzt und die API kann
angesprochen werden 🎉
Um jetzt noch die Hintergrundbilder runterladen zu koennen, habe ich
folgendes Script in bin/sm.sh gebaut, was rg (ripgrep, einfach
viel schneller als grep), youtube-dl (nur fuer
Vimeo und YouTube) und convert
(imagemagick) benoetigt:
Das Styling ist nun auch dank Tailwind CSS direkt im Shortcode
enthalten. Als Hover Farbe des Buttons habe ich #1db954 im Einsatz (um die genaue Farbe von Logos/Brands herauszufinden,
kann z.B. BrandColors genutzt werden).
Insgesamt sieht der Shortcode dann wie folgt aus:
{{<spotifyalbum25r7pEf31viAbsoVHC6bQ4>}}
Da wie oben beschrieben der access_token nur fuer eine Stunde gueltig
ist, muesste ich lokal entweder jede Stunde Hugo neu starten oder den
Parameter --ignoreCache=true anhaengen:
hugo server -v -D --ignoreCache=true
Da beides mega nervig ist, gibt es den Spotify Shortcode nur als Bilder
😉
Spotify Einbindung mit Bild im HintergrundSpotify Einbindung nach Klick auf das Logo
Update (2024-07-07):
Vom Hugo Entwickler Joe Mooring gibt es
Spotify widgets , die ich aber so nicht nutzen
wuerde (DSGVO und so).
Wie bei osm schon beschrieben, habe ich den Code fuer
youtube auch fuer Vimeo verwendet, da mir auch hier der
Standard-Shortcode nicht weit
genug geht. Angepasst fuer Vimeo sieht
layouts/_shortcodes/vimeo.html so aus:
Das Styling ist wieder direkt im Shortcode, als Hover Farbe des Buttons
habe ich #1ab7ea genutzt.
Um mit der Vimeo-API zu reden, brauchen wir ein
Secret . Das koennen wir in Hugo mit Environment
Variablen einbinden. Hierzu kann die Loesung, die ich bei
Spotify beschrieben habe ebenfalls verwendet werden. Die
.envrc habe ich einfach mit der folgenden Zeile erweitert:
exportHUGO_SECRET_VIMEO="abc"
Um jetzt noch die Hintergrundbilder runterladen zu koennen, habe ich das
Script bin/sm.sh von Spotify erweitert:
Und ebenfalls wie bei vimeo kann auch das Shellscript zum Runterladen
der Hintergruende genutzt werden. Das waere noch was fuer meine
TODO-Liste, dass das via Pipeline passieren kann (der Durchlauf wuerde
dann aber laenger dauern).
Mehrsprachigkeit ist mit Hugo recht leicht moeglich . Eine
Loesung fuer einzelne Artikel/Seiten etc. wird bei Fryboyter
beschrieben . Noch bin ich unsicher, ob ich das
ueberhaupt will, daher lasse ich das erstmal offen.
Zu ueberlegen waere dann noch, wie die URL aufgebaut sein soll, z.B.
/en/artikel/ oder /artikel-en/ oder /artikel/en/ oder …
Weil ich meine Rezepte bei Tandoor importieren wollte,
ist mir aufgefallen, dass es dafuer eine Loesung namens
structured data gibt, damit das auch einfach gelingt und
schoen aussieht.
Also habe ich mal mit ein wenig Hilfe meine Rezepte umgebaut, sodass sie
auch valides structured data ausspucken. Die
Kategorien usw. habe ich mir ein bisschen bei der Rezepteingabe bei
Chefkoch abgeguckt. Weitere Quellen:
Testen laesst sich das dann mit dem Test fuer
Rich-Suchergebnisse .
Bei der weiteren Beschaeftigung damit, habe ich es mal zumindest noch
fuer die Startseite eingebaut. Weitere Seiten werden vermutlich folgen.
Die Einbindung ist recht simpel und habe ich mir in diesem
hervorragenden Repository etwas abgeguckt. Ich habe
einfach in meiner layouts/baseof.html folgendes vor dem schliessenden
hinzugefuegt:
{{ partial "schema/schema.html" . }}
head>
Das Partial layouts/_partials/schema/schema.html sieht dann so aus:
Im Laufe der Jahre fielen mir immer wieder neue und vor allem kuerzere
Domains ein. Schliesslich habe ich mich fuer uxg.ch entschieden.
Warum? Auf vielen Geraeten lautet mein Username seit langem benjo, was
(abgeleitet von der Caesar-Verschluesselung ) ein ROT1
von admin ist. Da es keine TLD .jo gibt, habe ich einfach mal
durchrotiert und bin bei “ROT20” haengen geblieben. Die Domain war
verfuegbar, ist kurz (gerade im Vergleich zu yhaupenthal.org),
unterstuetzt DNSSEC und war nicht mega teuer, also habe ich
sie gekauft 🎉
Im Repo selbst muessen wir nun noch Secrets anlegen , die
die entsprechenden Daten enthalten. Also z.B. das Secret fuer die
YouTube API oder die SSH-Daten zum Server.
Update (2024-03-30):
Bei jedem Push werden erst 2 Testjobs ausgefuehrt (die ich jetzt via
reusable Workflow einbinde) und bei erfolgreichem
Status der 3. Job (der ein bisschen von Composite
Actions Gebrauch macht):
Auch meine Shellscripts will ich fortlaufend ueberpruefen und nutze
hierzu wieder ALE mit dem Tool shellcheck .
Build & Deploy
Waren beide vorherigen Jobs erfolgreich, folgt der dritte. Dieser
checkt erstmal das Repo aus (mit History fuer Git Info
Variablen ), installiert dann node.js , Hugo
und die npm-Pakete , die in der packages.json
angegeben sind. Schliesslich wird unsere Website mit
Minifizierung von Hugo gebaut und in einem weiteren
Schritt auf unseren Webserver hochgeladen. Auf entsprechende
Vorkehrungen auf dem Server gehe ich jetzt nicht ein, aber ein
Artikel dazu (siehe Hosting) ist in
Arbeit. Ebenso das Ersetzen von npm durch Hugo
Modules .
Ansonsten funktioniert die ganze Magie ueber die .gitlab-ci.yml, was
im Prinzip die gleichen Steps durchlaeuft wie die Action bei
GitHub (nur mit evtl. alten Paketen, weil ich die
Docker Images schon laenger nicht mehr aktualisiert
habe):
Es reicht dann folgender Befehl, um eine Datei anzulegen:
$ hugo new block/beispiel.md
/path/to/website/content/block/beispiel.md created
Diese Datei koennen wir nun oeffnen und beliebig aendern. Die Datei wird
anschliessend zum Git Index hinzugefuegt (git add content/block/beispiel.md), commited (git commit -va) und die
Aenderungen gepusht (git push origin main).
Der Push loest dann auf GitHub die oben beschriebene
Action aus und wir sollten nach kurzer Zeit eine neue
Version auf der Website sehen 🎉
Die ganzen technischen Dinge im Hintergrund (also Server an sich, ssh,
nginx usw.) versuche ich noch in einem anderen Beitrag zu beschreiben.
Und … das wars! Ueber 3 Jahre Arbeit, um meine Website auf einen neuen
technischen Stand zu heben 🙈 😅 🎉
Ubuntu Touch OTA-22 ist heute erschienen und führt Unterstützung von FM-Radio ein, um echten analogen Radioempfang auf unterstützten Geräten zu ermöglichen. Im Moment ist nur die Daemon-Implementierung in der OTA-22-Version enthalten, während eine FM-Radio-Anwendung in den nächsten Wochen im App Store verfügbar sein sollte.
Ubuntu Touch OTA-22 bringt auch gute Nachrichten für Besitzer anderer Geräte dank der Implementierung von WebGL-Unterstützung, die ein schnelleres 3D-Rendering ermöglicht. Darüber hinaus folgen die QQC2-Apps nun dem Systemthema und die Kameraunterstützung wurde in den Morph-Webbrowser integriert, sodass die Nutzer nun endlich Videoanrufe tätigen können.
"Dies ist wahrscheinlich die wichtigste Funktion dieses OTAs", so UBports. "Viele Leute haben uns gebeten, Videoanrufe als Option anzubieten. Jetzt läuft noch immer im Browser, aber wir denken, dass es bereits eine grosse Erleichterung sein kann. Und es ist der Türöffner für Videogespräche in Apps."
Es gibt auch gute Nachrichten für Volla Phone X-Besitzer im OTA-22-Update, das Unterstützung für den Fingerabdruckleser hinzufügt und verschiedene Probleme behebt, die Nutzer mit der vorherigen Version hatten. Dies alles ist möglich dank des Wechsels zu einer neueren Basis für das System-Image, Halium 10.
Darüber hinaus können OnePlus 5 und OnePlus 5T-Besitzer jetzt einen vollständigen Ubuntu Touch-Port geniessen, der sofort funktioniert, und Google Pixel 3a und Google Pixel 3a XL-Besitzer erhalten mit diesem Update eine bessere Klangqualität und Lautstärkeregelung sowie einen sogenannten "Booster-Modus" aktiviert, der die Anzahl der CPUs begrenzt und andere Batteriesparoptionen konfiguriert, wenn der Bildschirm ausgeschaltet ist.
Zu guter Letzt fügt das OTA-22-Update dem Begrüssungsbildschirm (Sperrbildschirm) Unterstützung für die Rotation sowie ein neues Layout für die Notrufleiste am unteren Rand hinzu, und die Dialer-App erhielt eine automatische Vervollständigung des Wähltastenfelds, damit man schneller auf Kontakte zugreifen kann.
Ausserdem wurden einige Bugs beseitigt, um das Beschneiden von MMS-Bildern in der Messaging-App zu verhindern, den Shader-Cache für QML zu verbessern, den Fingerabdruckleser auf OnePlus 5T-Geräten funktionsfähig zu machen und zu ermöglichen, dass sie in den Ruhezustand zurückkehren, wenn eine Push-Benachrichtigung eintrifft, sowie die Kamerarechte auf einigen Geräten durchzusetzen.
Das Ubuntu Touch OTA-22-Update wird jetzt auf alle unterstützten Geräte ausgerollt.
Es gibt eine Vielzahl von grafische Markdown Editor für Linux, mit unterschiedlichen Schwerpunkten. Zettlr vereint die Fähigkeiten eines mächtigen Bearbeitungsprogramms mit einer Verschlagwortungsfunktion und vielen weiteren Extras. Insbesondere bei komplexen Texten, helfen diese dabei, die Übersicht zu behalten.
Tags lassen sich pro Dokument hinzufügen. Die zentrale Suche ermöglicht das schnelle Auffinden zuvor definierter Schlagwörter.
Eine weitere Möglichkeit stellt der sogenannte Zettelkasten dar. Mit dessen Hilfe lassen sich interne Dokumente verlinken, ähnlich wie bei einem Wiki. Bei einem Klick auf einen solchen Link mit gedrückter Ctrl-Taste wird das Zieldokument angezeigt und gleichzeitig in der Seitenleiste eine Volltextsuche nach dem Wort durchgeführt.
Zettlr bietet Exportmöglichkeiten in gängige Formate, welche mittels Pandoc/LaTeX realisiert wurden. Die Anwendung integriert eine vollwertige Rechtschreibkorrektur und bietet einen Dark-Mode, welcher sich bei Bedarf auch zeitgesteuert aktivieren lässt.
Der integrierte und optional nutzbare Pomodoro-Timer hilft dabei, die Bildschirmzeit zu reduzieren und Pausen einzuhalten.
Es stehen Pakete für Debian und Fedora, sowie AppImages zum Download zur Verfügung.
Mit dem Update auf Firefox 97.0.1 blockiert Mozilla die aktuelle Version einer von der Sicherheits-Software WebRoot SecureAnywhere injizierten DLL-Datei unter Windows, da diese zur völligen Unbenutzbarkeit von Firefox führen konnte. WebRoot wird das Problem in einem zukünfigten Update seiner Sicherheits-Software beheben.
Außerdem hat Mozilla einen Fehler behoben, der für manche Nutzer mit deaktivierter Sitzungswiederherstellung fälschlicherweise zu einem Bildschirm beim Firefox-Start führte, der aussagte, dass Firefox die Tabs nicht wiederherstellen konnte.
Behoben wurde auch ein Fehler, der auf der Video-Plattform Hulu dafür sorgte, dass der Bild-im-Bild-Modus nicht aktiviert werden konnte und das Video stattdessen pausierte. Ein anderes behobenes Problem betrifft die Video-Plattform TikTok, wo es sein konnte, dass Videos, welche von der Profilseite eines Nutzers geöffnet werden sollten, nicht öffneten.
Schließlich wurde noch eine Absturzursache behoben, welche ausschließlich Windows 7 betroffen hat, sowie eine weitere Absturzursache, welche ausschließlich Linux betroffen hat.
Zu einem Smart Home gehört es fast selbstverständlich, dass der Verbrauch von Energie aufgezeichnet wird. Der Stromzähler ist eine der wesentlichen Energiezählern im Haushalt, auch der Gaszähler ist sehr wichtig. Vor allem in Haushalten, in denen der primäre Energieträger Erdgas ist, ist der Gasverbrauch essenziell und wird im Smart Home auch optimiert. Das ist, zumindest für meine Begriffe, eine der wesentlichen Aufgaben des Smart Homes.
Das Schöne an den Gaszähler ist es, dass sie sich in der Regel sehr einfach auslesen lassen. Es ist keine komplizierten und teuren Geräte dafür notwendig. Bei den meisten Gaszählern reicht nämlich ein einfacher Reed-Kontakt aus, die es für einige Cent bei Ebay oder anderen Shops zu kaufen gibt. Als Intelligenz wird der sehr vielseitige ESP8266 verwendet. Dieser ist sehr energiesparend, hat integriertes WLAN, lässt sich verhältnismäßig einfach einrichten und kostet ebenfalls nur sehr wenig Geld.
Wenn der Gaszähler eine Aufschrift wie „1 im = 0,01m³“ trägt, lässt er sich mit wenig Aufwand digitalisieren. Ein Reed-Schalter könnte bereits genügen, um den Gaszähler ins Smart Home einzubinden.
Hardware: ESP8266 und Reed-Kontakt verlöten
Die Einkaufsliste für diesen Sensor:
ESP8266, beispielsweise den Wemos D1 Mini
Reed-Kontakt
optional: 5V Netzteil
optional: Schrumpfschlauchsortiment
Für einen geübten Maker ist diese Aufgabe im Handumdrehen erledigt. Für nicht geübte Maker ist es das perfekte Einsteigerprojekt. Es sind nur sehr wenige Lötstellen zu setzen und man kann kaum etwas falsch machen. Beim ESP8266, in meinem Fall ein Wemos D1 mini, müssen nur die beiden Pinleisten angelötet werden. Für Minimalisten würde sogar je ein Pin bei G (Ground) und D1 (GPIO5) reichen. An diese Pins gehören jeweils die Kabel, idealerweise Litzen 0,15mm², an deren Ende der Reed-Kontakt gehört. Bei diesem Schalter muss man keine Richtung beachten, man kann ich nicht falsch herum anlöten. Das fertige Produkt sieht dann so aus. Ich habe noch versucht, die Lötstellen mit Schrumpfschlauch zu verschönern. Das ist optional.
Update (02.05.2022) Weiterhin habe ich eine optionale LED zur Visualisierung des Signals eingebracht. Diese blinkt immer dann, wenn der Reed-Kontakt schaltet. Das ist vor allem dann sehr nützlich, wenn man den Reed-Schalter am Gaszähler anbringt. Die LED ist eine Hilfe, sie ist aber nicht zwingend nötig. Ihren Vorwiderstand kann man über Online-Tools berechnen, bei mir waren es 220 Ohm.
Der Schaltplan mit optionaler LEDESP8266 an der Pinleiste mit einem Reed-Schalter verlötet. Der Reed-Schalter geht auf Pin G und Pin D1
ESPHome auf ESP8266 installieren unter Windows 10
Unter Windows 10 lässt sich über den „Microsoft Store“ Ubuntu installieren. Das ist der kleine Umweg, den ich häufig gehe, um ein fast vollständiges Linux unter Windows 10 zum laufen zu bringen. Dass es leider nicht vollständig ist, sieht man den nun folgenden, etwas umständlichen Herangehensweise, wie man ESPHome auf dem ESP8266 installiert.
Wer ein vollständiges hass.io bzw. Home Assistant hat, kann das übrigens über den Addon-Store mit dem Add-on „ESPHome“ deutlich beschleunigen. Da ich aber, wie bereits beschrieben, Home Assistant als Container laufen habe, ist für mich der Umweg notwendig.
Man startet Ubuntu unter Windows und gelangt in das Terminal. Dort installiert man sich (falls noch nicht geschehen) Python 3 und das nötige Paket „esphome“ aus dem Python-Repsitory. Anschließend prüft man, ob die Installation geklappt hat, indem man sich die Versionsnummer ausgeben lässt.
Der Einfachheit halber empfehle ich, den Wizard von ESPHome zu verwenden. Er wird benutzt, um die *.yaml zu erstellen. Genau wie bei Home Assistant ist sie dafür da, den Controller zu konfigurieren. Der Wizard zeigt einem glücklicherweise gleich alle möglichen Alternativen auf, die man eingeben kann. Beantwortet also wahrheitsgemäß die 4 Fragen den Wizards und wir erhalten eine Konfigurationsdatei mit dem angegebenen Namen. Ich habe hier willkürlich gaszaehler.yaml gewählt.
Die nun folgende Datei sieht dann beispielsweise so aus:
esphome:
name: gaszaehler
esp8266:
board: d1_mini
# Enable logging
logger:
# Enable Home Assistant API
api:
password: "1234"
ota:
password: "1234"
wifi:
ssid: "hier die Wifi-SSID eintragen"
password: "hier das Wifi Passwort eintragen"
manual_ip:
static_ip: "auf Wunsch"
gateway: "IP-Adresse des Gateways"
subnet: "Subnet Maske"
# Enable fallback hotspot (captive portal) in case wifi connection fails
ap:
ssid: "Gaszaehler Fallback Hotspot"
password: "hier steht automatisch ein Passwort"
captive_portal:
Das Fallback-Wifi wird gebraucht, falls der Sensor das eigentliche WLAN nicht erreichen kann. Dann baut der ESP8266 eigenständig ein WLAN auf, über das er sich konfigurieren lässt.
Update (02.05.2022) Vor diesem Update habe ich den Pulse_counter von ESPHome verwendet. Dieser liefert leider keine zuverlässigen Werte. Gleiches gilt für den pulse_meter, der eigentlich besser sein sollte. Stattdessen bin ich nach einiger Tüftelei wieder bei dem binary_sensor herausgekommen, der wunderbar funktioniert. Zusätzlich ist eine LED auf GPIO0 angebracht, die schaltet, sobald der Reed-Schalter zieht. Damit könnt ihr live am Gerät sehen, ob ein Puls anliegt. Sie ist nur eine Hilfe und nicht zwingend erforderlich.
globals:
- id: total_pulses
type: int
restore_value: false
initial_value: '0' # hier kann der Gaszählerstand initialisiert werden
binary_sensor:
- platform: gpio
id: internal_pulse_counter
pin:
number: GPIO5
mode: INPUT_PULLUP
name: "Live-Impuls"
filters:
- delayed_on: 10ms
on_press:
then:
- lambda: id(total_pulses) += 1;
- output.turn_off: led # optional: für eine LED, die den Gaszählerpuls visualisiert
on_release:
then:
- output.turn_on: led # optional: für eine LED, die den Gaszählerpuls visualisiert
sensor:
- platform: template
name: "Gasverbrauch"
device_class: gas
unit_of_measurement: "m³"
state_class: "total_increasing"
icon: "mdi:fire"
accuracy_decimals: 2
lambda: |-
return id(total_pulses) * 0.01;
# Optional: Diese LED soll blinken, sobald ein Signal vom Gaszähler erkannt wird
output:
- platform: gpio
pin: GPIO0
id: 'led'
Fertig mit der Konfiguration. Wir speichern mit Strg + O und schließen Nano mit Strg + X
Mit dem folgenden Befehl wird der Code für den ESP8266 kompiliert. Ich habe es leider nicht geschafft, ihn direkt per USB-Kabel auf meinen Controller zu bekommen. Daher bin ich einen Umweg gegangen.
$ esphome run gaszaehler.yaml
Das endet mit einer Fehlermeldung (connection failed bad indicator errno=11), dass der Code nicht auf den Controller gebracht werden konnte. Stattdessen kopieren wir den Code auf das Laufwerk C: unter Windows und arbeiten von dort aus weiter (sorry Leute!!).
Mittels ESPHome-Flasher, den es auch für Windows gibt und der nicht installiert werden muss (!!) geht es weiter. Die eben kopierte Datei auswählen, den ESP8266 mit USB am PC anstöpseln und den entsprechenden COM-Port auswählen (bei mir wurde nur einer angezeigt). Bestätigen, und warten bis es fertig ist.
ESPHome in Home Assistant installieren
Mit der Entität „ESPHome“ kann der Sensor in den Home Assistant eingebunden werden. Das geht sehr fix, es muss nur die IP-Adresse und das festgelegte Passwort eingegeben werden. Damit er auch korrekt als Energiequelle erkannt wird, muss man noch folgende Zeilen in die configuration.yaml anfügen, besser noch, in die sensor.yaml
Update (15.04.2022): Manchmal fällt der ESP kurzzeitig aus, was den Gasverbrauch kurzfristig auf 0 m³ setzt. Sobald er wieder da ist, gibt es einen unlogischen Peak in der Statistik. Dieser wird über die kleine IF-Schleife herausgefiltert.
- platform: template
sensors:
# Gaszähler, kommend von ESPHome, aufbereiten für Energy
gasincubicmeter:
value_template: >
{% if states('sensor.gasverbrauch') | float == 0 %}
{{ states('sensor.gasincubicmeter') }}
{% else %}
{{ states('sensor.gasverbrauch') | float }}
{% endif %}
unit_of_measurement: m³
device_class: gas
attribute_templates:
state_class: total_increasing
Nach einem Neustart des Servers klickt man im Home Assistant auf „Einstellungen“, „Energie“ und klickt auf den Gaszähler. Dort taucht nun die neue Entität gasincubicmeter auf und kann ausgewählt werden.
In Home Assistant kann über Einstellungen → Energie eine neue Gasquelle hinzugefügt werdenDer Gasverbrauch wird auf dem Energie-Dashboard von Home Assistant angezeigt
Reed-Schalter am Gaszähler positionieren
Wer Zugriff auf einen 3D-Drucker hat, sollte sich bei Thingiverse mal umsehen, ob dort ein Halter für seinen Gaszähler vorhanden ist. Die Chance dort, oder woanders, einen zu finden, halte ich für sehr hoch. Andernfalls kann man mit etwas Geschick und gutem Klebeband den Schalter direkt am Gaszähler montieren. Er muss in der vorgesehenen Kerbe möglichst genau unter der letzten Ziffer positioniert werden. Wer darauf achtet, wird bemerken, dass die letzte drehende Ziffer einen kleinen Magneten hat. Genau darunter muss der Reed-Schalter geklebt werden.
Kinoite gehören zur Mineralklasse der 'Silikate und Germanate'. Der bläulich-silbern schimmernde Glanz hat wohl die Entwickler des Fedora-Abkömmlings zur Namensgebung inspiriert.
Ähnlich wie Fedora Silverblue gehört Kinoite zu den sogenannten immutable Systemen, das heisst das Basissystem ist grundsätzlich unveränderlich. Die Distributionen unterscheiden sich vorwiegend in der Wahl der Standard-Desktopumgebung. Im Gegensatz zu Silverblue, kommt bei Kinoite KDE Plasma zum Einsatz. Grundlegende Mechanismen wie rpm-ostree sind auch dort gültig.
Die Installation erfolgt mit dem von Fedora bekannten Anaconda Installationsprogramms, wobei die Einrichtung der Benutzerkonten von Silverblue abweicht. Der Root-Account ist standardmässig deaktiviert, der anzulegende Benutzer erhält allerdings erst nach Auswahl der entsprechenden Option, die Möglichkeit Administratoren-Rechte zu erlangen. Wurde dies nicht aktiv konfiguriert, lässt sich die Installation nicht starten.
Wurde diese Hürde erst einmal genommen, präsentiert sich Kinoite mit einem leicht angepassten KDE Plasma Desktop. Damit einher geht die grafische Softwareverwaltung mit dem Programm Discover. Wie auch bei Silverblue ist das Flathub Repository standardmässig nicht aktiviert. Die Möglichkeit 3rd Party Repositories über einen Assistenten zu integrieren, wie es bei Silverblue der Fall ist, gibt es nicht. Sobald Flathub anhand der offiziellen Anleitung des Projektes eingebunden wurde, lassen sich Applikationen aus dem Repository über Discover installieren und das System so erweitern.
Damit stellt Kinoite eine verlässliche Alternative für Nutzer des KDE Plasma Desktops dar und hebt sich aufgrund der neuen Systemarchitektur von klassischen Linux-Distributionen ab.
Fedora Silverblue und Kinoite sind primär auf die Nutzung von Flatpaks ausgelegt. Dennoch kann es in einigen Fällen notwendig sein, RPM Pakete zu installieren. Möglich macht dies rpm-ostree, welches die benötigten Anwendungen als Overlay einbinden kann.
Bisher bietet rpm-ostree keine integrierte Suche, wie beispielsweise dnf. Sollte der Paketname unbekannt sein, kann dnf in einer toolbox zur Hilfe genommen werden.
Falls bisher noch keine toolbox erzeugt wurde, lässt sich dies mit dem folgenden Befehl nachholen:
toolbox create -y
Die dnf Suche lässt sich daraufhin innerhalb der toolbox wie folgt ausführen:
toolbox run dnf search nano
Nachdem der passende Paketname ermittelt wurde, erfolgt die eigentliche Installation mit rpm-ostree:
rpm-ostree install nano
Die Änderungen werden nach einem Neustart des Systems appliziert.
Alternativ lässt sich die experimentelle Funktion apply-live nutzen:
In den letzten Wochen haben wir einige Beiträge zum Thema 'Linux für Einsteiger' geschrieben und in diesem Artikel ein Fazit gezogen. Es wurden 9 verschiedene Distros mit unterschiedlichen Konzepten und Desktop-Umgebungen betrachtet. Bei der Vorauswahl haben wir nur solche Systeme in Erwägung gezogen, die wir für Einsteiger:innen geeignet hielten. Deshalb gab es keine Gewinner und Verlierer, sondern eine Palette an Distributionen, die wir empfohlen haben.
Nach einigem Nachdenken, bin ich zum Schluss gekommen, dass die Desktop-Umgebung für Anfänger:innen wichtiger ist, als die darunter liegende Distribution. Dem mag man widersprechen, weil es nicht lange dauert, bis die Anwender die Unterschiede entdecken. Dennoch, der erste Eindruck zählt, und dieser wird von der Oberfläche und nicht vom Unterbau geprägt.
'Seeing is believing', sagt der Volksmund. Man muss etwas sehen, um es zu glauben; sichtbare Fakten lassen sich nicht leugnen. Die Einsteigerin sieht den Installationsprozess, die Einführung und den Desktop. Bei der aktuellen Aufmerksamkeitsspanne, die bei wenigen Minuten liegt, müssen diese Erfahrungen ausreichen, um einen Einsteiger von der gewählten Distro/Desktop-Kombination zu überzeugen.
'The Linux Experiment' zu diesem Thema
Der grosse Vorteil von GNU/Linux-Distributionen und den Desktop-Umgebungen, ist deren Vielfalt. Das muss man nicht als Verwirrung, sondern als freie Auswahl ansehen. Auch beim Wocheneinkauf schätzt man die Wahl zwischen den Barbecue-Sossen, Joghurts und Pasta-Sorten.
Daher empfehle ich in diesem Nachtrag, sich an den grossen und etablierten Desktop-Umgebungen zu orientieren. Diese sind:
KDE-Plasma : Windows-ähnlich mit vielen Einstellungsmöglichkeiten
GNOME-Shell : Modern und auf das Wesentliche reduziert
Xfce : Solide, klassisch zu bedienen und für ältere Computer geeignet
Selbstverständlich gibt es weitere Desktops, die für spezielle Anwendungsfälle besser geeignet sind. Das geht jedoch über das hinaus, was eine Einsteigerin interessieren sollte. Denn für Euch, die in die GNU/Linux-Welt einsteigen möchtet, reicht die Auswahl zwischen diesen drei Desktops vollkommen aus. Alles andere kommt später.
Mein Tipp: schau Dir die drei Desktops an, und wähle das Erscheinungsbild, welches Dir am besten gefällt. Alle relevanten Distributionen bieten diese drei Desktop-Umgebungen an. Wenn es später um die beste Distro für Deine Zwecke geht, wendest Du Dich an die Community und lässt Dich beraten.
Unter macOS hatte ich mit LibreOffice seit einiger Zeit das Problem, dass es nur weiße Seiten ausdruckte. Auch die entsprechende Druckvorschau unter macOS war leer. Das Erzeugen von PDFs und der anschließende Druck hingegen funktionierten ohne Probleme. Die Druckvorschau zeigt nur leere Seiten Verursacht wird der Fehler wohl durch die Bibliothek Skia, bei welcher es sich um eine freie 2D…
Dies ist der Beginn meines zweiten Container-Projekts. Nach Kanboard im Container möchte ich diesmal eine Nextcloud-Instanz als Container, zusammen mit einem Datenbank-Container, in einem Podman-Pod betreiben.
Da ein einzelner Artikel vermutlich zu lang wird, teile ich das Projekt in mehrere Artikel auf. Wie viele es genau werden, kann ich jetzt noch nicht sagen. Am Ende der Reihe werde ich hier eine Übersicht einführen und die einzelnen Teilen entsprechend miteinander verbinden.
In diesem ersten Teil geht es um meine Motivation, das eigentliche Ziel und den groben Plan.
Was Leser dieser Reihe erwartet
Ihr könnt mich durch diese Reihe begleiten und euch von meinen Erlebnissen und Erkenntnissen unterhalten lassen. Dabei dürft ihr nicht annehmen, dass es sich bei dem von mir beschriebenen Vorgehen um eine gute Praxis handelt. Hier gilt eher: Der Weg ist das Ziel.
Ihr seid herzlich eingeladen, die Artikel zu kommentieren und über das Vorgehen und Alternativen dazu zu diskutieren. Gern in der Kommentarsektion unter den jeweiligen Beiträgen oder als Artikel in euren eigenen Blogs.
Ich plane die Artikel im Wochenrhythmus, wenigstens monatlich, zu veröffentlichen. Bitte verzeiht, wenn es etwas unregelmäßig wird. Dies ist ein Hobby, dem nur begrenzt Zeit zur Verfügung steht.
Motivation
Bei Linux-Containern handelt es sich um eine Technologie, die gekommen ist, um zu bleiben. Sie hat bereits in vielen Branchen Fuß gefasst und immer mehr Projekte bieten ihre Anwendungen zusätzlich oder ausschließlich in Form von Containern an.
Als Sysadmin mittleren Alters werden mich Linux-Container sicher noch viele Jahre begleiten. Um praktische Erfahrungen mit dem Betrieb zu sammeln, möchte ich einige private Projekte in Containern betreiben.
Beruflich arbeite ich überwiegend mit RHEL. Red Hat engagiert sich stark in den Projekten Ansible und Podman, welche ich auch unter anderen Distributionen, wie z.B. Debian, einsetze. Ich möchte das Projekt als Chance nutzen, mein Wissen auch in diesen Werkzeugen zu festigen und auszubauen.
Ich spiele schon seit einiger Zeit mit dem Gedanken, wieder eine eigene Nextcloud-Instanz zu betreiben. Da auf dem zur Verfügung stehenden Server bereits eine Nextcloud-Instanz läuft und ich meine Anwendung von der bestehenden Instanz getrennt und möglichst losgelöst vom Betriebssystem betreiben möchte, habe ich mich entschieden, Nextcloud im Container zu betreiben.
Ziele
Ziel dieses Projekts sind das Deployment und der Betrieb einer Nextcloud-Instanz als Podman-Pod. Im Einzelnen sollen folgende Ziele erreicht werden:
Entwicklung eines wiederverwendbaren Verfahrens zum Deployment einer Nextcloud im Container
Persistente Speicherung von Konfigurations- und inhaltlichen Daten im Dateisystem des Hosts
Konfiguration eines Reverse-Proxies (NGINX) für den Zugriff auf die Nextcloud-Instanz
Konfiguration von Backup und Restore für Konfiguration und Inhalte der Nextcloud-Instanz
Konfiguration und Test automatischer durch Ansible gesteuerter Updates
Umgebung
Für die Umsetzung des Projekts steht mir ein Virtual Private Server (VPS) mit genügend Ressourcen zur Verfügung. Dieser wird in einem Rechenzentrum in Deutschland betrieben. Auf diesem sind Debian Bullseye, NGINX, ein OpenSSH-Server, Podman 3.0.1 (rootless) und Python 3.9.2 installiert. Damit erfüllt dieses System die Voraussetzungen, um mit Ansible konfiguriert zu werden und Container ausführen zu können.
Ansible selbst läuft in meiner privaten Arbeitsumgebung auf meinem Debian-PC und einem Fedora-35-Notebook.
Methodik und verwendete Werkzeuge
Zu Beginn habe ich mich etwas in der Nextcloud-Dokumentation und den verfügbaren Nextcloud-Images belesen. Besagte Dokumentation sowie die der verwendeten Werkzeuge sind im folgenden Abschnitt verlinkt.
Um die oben formulierten Ziele zu erreichen, werde ich in einem Python Virtual Environment eine Ansible-Version installieren, mit der ich die Collection containers.podman nutzen kann. Hiermit werde ich eine Ansible-Rolle entwickeln, die ich wiederverwenden kann, um Nextcloud-Instanzen in einer rootless-Podman-Umgebung zu deployen. Die Ansible-Rolle wird anschließend auf meinem GitHub-Account veröffentlicht.
Die Konfiguration von NGINX und acme.sh für die TLS-Zertifikate erfolgt manuell.
Quellen und weiterführende Links
In diesem Abschnitt liste ich Links zu Artikeln und Dokumentationen auf, welche ich im Vorfeld gelesen habe und deren Kenntnis ich für die Umsetzung als nützlich erachte. Zur besseren Übersicht gliedere ich diese in die Unterabschnitte Hintergrundwissen, Dokumentation und Eigene Artikel.
Der Sinn eines verifizierten Systemstart (engl. „verified boot“) ist sicherzustellen, dass beim Start Komponenten aus vertrauenswürdigen Quellen geladen werden und es Angreifern nicht gelingt, manipulativ in den Prozess einzugreifen. Grundsätzlich ist vieles davon Linux nicht fremd, aber wird zum Teil aktiv unterlaufen.
Natürlich handelt es sich dabei um „advanced“ Sachen. Wer sein System nicht verschlüsselt, andauernd irgendwelche Programme von Dritten herrunter lädt und sich Kernel aus irgendwelchen PPAs installiert, der hat dadurch überhaupt keinen Sicherheitsgewinn. Ich respektiere es auch, wenn man solche „Trusted Computing“-Konzepte ablehnt oder ihnen zumindest misstraut. Ich ermuntere dennoch dazu, hier nicht einfach irgendwas nachzuplappern, weil (insbesondere in der deutschen Community?) in dem Bereich viele urbane Legenden kursieren. Neben abstrakten Informationsquellen ist meine konkrete Arbeitsgrundlage für viele Experimente das Arch Linux-Wiki und das ist nun wirklich kein Vertreter von „Corporate Linux“.
Der Blick über den Tellerrand
Der verifizierte Systemstart ist dabei keinesfalls irgendwie exotisch. Systeme wie iOS oder Android haben das ebenso implementiert, wie Windows 11 oder macOS. Das Prinzip ist einfach: Es wird eine vollständige Vertrauenskette aufgebaut. Angefangen von einer vertrauenswürdigen (Hardware-)Wurzel, bei der jeweils eine geladene Stufe die nächste authentifiziert. Also von der Hardware, über den Bootloader zu den entsprechenden Systempartitionen bis hin zu den Benutzerdaten. Das entsprechende Verfahren kann z. B. hier für Android nachgelesen oder ist hier sehr anschaulich viel Windows 11 (vor allem Abbildung 1 für Leser ohne Lust auf langwierige technische Inhalte) dargestellt. Solche Verfahren können noch mit einem Rollback-Schutz und anderen Sachen kombiniert werden, aber das führt jetzt hier zu weit.
Was kann Linux theoretisch?
Folgende Boot-Abfolge kann Linux bzw professionelle Linux-Distributionen momentan theoretisch bieten:
UEFI startet shim (was letztlich nur eine Zertifikatesammlung mit Signatur von Microsoft ist). Das kann in das s. g. „TPM boot measure“ (keine Ahnung, wie man das gut übersetzt?) einbezogen werden.
Shim ruft den Bootloader (i. d. R. GRUB) auf, der mit einem Schlüssel des Distributors signiert ist. GRUB kann theoretisch in das „TPM boot measure“ einbezogen werden.
Alternativ ist theoretisch der direkte Start über ein Unified Kernel Image möglich.
Der Bootloader ruft den Kernel auf und übergibt initrd. Der Kernel ist durch den Distributor signiert, initrd ist nicht signiert oder validiert. Kernel und initrd können theoretisch in „TPM boot measure“ einbezogen werden.
Bei verschlüsselten Systemen fragt initrd nun nach dem Passwort für die verschlüsselte Root-Partition. Es erfolgt keine Verifikation, ob initrd manipuliert oder ähnliches wurde. Es erfolgt der Übergang ins Root-Dateisystem. Die per LUKS verschlüsselte root-Partition kann an den TPM Secure Boot Status gebunden werden.
Abschließend erfolgt eine Anmeldung des Benutzers in der Loginmaske der Desktopumgebung. Die Daten sind bereits vorher entschlüsselt, sofern der Administrator nicht eine individuelle Konfiguration mit systemd-homed, eCryptFS oder separaten LUKS-Partitionen pro Benutzer eingerichtet hat.
Was macht Linux faktisch?
Secure Boot wurde deaktiviert, weil man irgendwo gelesen hat, dass man das tun sollte.
TPM ist ebenfalls deaktiviert, auf der Modul-Blacklist oder wird einfach nur nicht beachtet. Selbst wenn TPM nicht deaktiviert ist, macht eine Einbeziehung in GRUB oder initrd momentan wegen des unzureichenden Implementierungsgrades keinen Sinn.
GRUB lädt ein nicht signiertes initrd und einen nicht signierten Kernel.
Bei verschlüsselten Systemen fragt initrd nun nach dem Passwort für die verschlüsselte Root-Partition. Es erfolgt keine Verifikation, ob initrd manipuliert oder ähnliches wurde. Es erfolgt der Übergang ins Root-Dateisystem.
Abschließend erfolgt eine Anmeldung des Benutzers in der Loginmaske der Desktopumgebung. Die Anmeldung ist Makulatur, da die Daten bereits vorher entschlüsselt wurden, daher erfolgt oft ein einfacher Autologin.
Ist das ein Problem?
Das hängt wie bereits oben geschildert, von der Frage ab, welches Sicherungsbedürfnis man hat. Nutzt man sowieso keine Verschlüsselung, braucht man weitere Schutzmaßnahmen eh nicht. Insbesondere auf Entwicklungssystemen ohne schutzwürdige Daten verzichtet man häufiger auf Verschlüsselung. Hier kann man dann also auch nach Belieben mit nicht signierten Kernel, selbst gebauten Modulen etc. arbeiten.
Nutzt man eine Verschlüsselung nur, um Gelegenheitsblicke von neugierigen Kollegen, Freunden oder Familienmitgliedern zu entgehen, dann benötigt man weiterführende Maßnahmen ebenso eher nicht. Es sei denn man hat eine Tochter, die gerade an einer Bewerbung für den Geheimdienst als Hackerin arbeitet.
Hat man aber ein Schutzbedürfnis für sich selbst erkannt und nutzt ein vollständig verschlüsseltes Betriebssystem, um seine Daten sicher vor den Blicken professioneller Angreifer zu schützen, dann hat der aktuelle Zustand erhebliche Schwachstellen und einige zumindest seltsame Aspekte:
Man startet ein verschlüsseltes System von einer i.d.R. unverschlüsselten boot-Partition, ohne zu prüfen, was eigentlich mit initrd und Kernel passiert ist und gibt dort das Passwort ein. Dieses Problem wird aktuell gelöst durch eine verschlüsselte Boot-Partition, was aber GRUB immer mehr aufbläht und noch unwartbarer macht als es eh schon ist.
Das System lässt sich einfach kopieren und danach mit Brute Force so lange „quälen“ bis man drin ist. Die Verschlüsselung mit LUKS kennt dagegen keine Schutzmaßnahmen und verhindert das auch nicht.
Man gibt ein Passwort beim Start ein, um das Betriebssystem zu entschlüsseln und entschlüsselt nebenbei die Benutzerdaten. Der eigentliche Benutzerlogin ist nur Makulatur und weil das den meisten Anwendern klar ist, überspringen sie oft auch den Benutzerlogin per Autologin.
Benutzerdaten sind bei Multiuser-Systemen nur mit den UNIX-Rechten gegeneinander abgeschirmt und je nach Distribution nicht mal das.
Schlussbemerkung
Das Thema ist perspektivisch kein „Entweder-Oder“, sondern ein „Und“. So wie in der Vergangenheit immer die Möglichkeit bestand, nicht verschlüsselte Systeme zu nutzen, obwohl die Distributionen die LUKS-Verschlüsselung zunehmend prominenter in den Installationsroutinen platzierten, so wird auch der verifizierte Startvorgang Einzug halten für jene, die es benötigen oder dies zumindest glauben bzw. wohl eher fürchten. Alle anderen können, aber müssen dies nicht nutzen. Unstrittig ist jedoch, dass man aktuell ein bisschen hinter den anderen Betriebssystemen her rennt und nicht mal die Möglichkeiten ausreizt, die man schon hat. Spannend dürfte sein, was Enterprise-Distributionen wie SUSE Linux oder Red Hat Enterprise Linux hier in den nächsten Jahren umsetzen. Bei beiden Firmen ist man an den Themen dran.
Das war (voraussichtlich) der letzte Artikel zu diesem Thema für die nächste Zeit. Alle, die von Secure Boot, TPM, GRUB, verified Boot & Co schon genervt sind, können also entspannt in die Zukunft schauen 😉
Die Linux-Community, ihre Eigenheiten und komischen Ausprägungen beschäftigen mich schon länger. Das dürfte für viele Leser hier nichts Neues sein. Momentan frage ich mich aber, ob das Problem nicht sehr spezifisch die deutschsprachige Linux-Community betrifft?
Meine Beobachtung zu den Unterschieden bei Wikipedia hatte ich kürzlich schon mal hier dargelegt. Nun bin ich aufgrund eines anderen Themas auf die systemd-Artikel bei Wikipedia gestoßen. Schauen wir uns mal drei Artikel an, deren Sprache ich beherrsche:
Die Unterschiede sind eklatant. Das ist keineswegs ein „Wikipedia-Phänomen“, denn diese Artikel schreiben Prinzip-bedingt Autoren mit Affinität zum Thema Linux bzw. Mitglieder einer weiter gefassten „Linux-Community“.
Der englischsprachige Artikel ist sehr umfassend, was vermutlich an der größeren Autoren- und Leserschaft liegt. Es geht um Geschichte, technisches Design, die zugehörigen Komponenten, die Verbreitung unter den verschiedenen Linux-Distributionen und ganz am Schluss kommt die Rezeption bzw. Kritik an systemd, sowie alternative Implementierungen. Die spanischsprachige Wikipedia orientiert sich an der englischsprachigen Wikipedia, hat aber einen längeren Teil mit Anleitungscharakter und nur einen kurzen Kritikteil.
Bei der deutschen Wikipedia geht es ganz kurz um Geschichte und Funktion und dann auf knapp 7000 Zeichen um die Kritik an systemd. Dazu ist die Auswahl der Meldungen verglichen mit der englischsprachigen Version höchst tendenziös, da immer nur die Kritik und selten die Entscheidungen und Problemlösungen thematisiert werden. Repliken auf diese Kritik (Lennart Poetterings „The biggest Myths“), die in der englischsprachigen Wikipedia erwähnt werden, finden in der deutschsprachigen Wikipedia keinen Widerhall.
Der englischsprachige Leser hat am Ende der Lektüre einen guten Überblick über Geschichte, Design, Funktionen und Kritik an systemd. Dem deutschsprachigen Leser bleibt der Eindruck, eine katastrophale Technologie hätte sich irgendwie durchgesetzt.
Läuft da was falsch bei der deutschsprachigen Linux-Community? Ist das ein spezifisches Wikipedia-Problem? Mich würden da auch Meinungen bzw. Kommentare von Lesern interessieren, die vielleicht auch in anderssprachigen Linux-Communitys unterwegs sind.
Verschlüsselung für mobile Betriebssystem wie Android ist trivial und mit wenigen Einstellungen aktiviert. Wegen einiger Änderungen in der Vergangenheit gibt es für Android jedoch viele veraltete Informationen.
Verschlüsselung ist bei Desktop-Betriebssystemen wie Windows, Linux oder macOS eine peinliche Leerstelle. Obwohl es für alle drei Systeme leistungsfähige Lösungen gibt, verzichten alle Hersteller auf eine standardmäßige Aktivierung und Bewerben diese auch nicht aktiv. Während Windows und macOS sich wenigstens noch nachträglich verschlüsseln lassen, schauen Linux-Nutzer in die Röhre, wenn sie bei der Installation die entsprechenden Optionen nicht gesetzt haben.
Nicht so bei mobilen Betriebssystemen. Google und Apple haben in ihre Betriebssysteme für Tablets und Smartphones selbstverständlich leistungsstarke Verschlüsselungsmethoden implementiert, die im Hintergrund automatisch aktiviert werden, sobald der Anwender die Codesperre (sowie ggf. biometrische Verfahren) aktiviert. Bei Android hat Google hier in der Vergangenheit einige Änderungen vorgenommen, weshalb viele Berichte dazu veraltet sind und teils unverständliche Kürzel kursieren.
FDE: Full Disk Encryption
Die FDE-Verschlüsselung stand am Anfang. Technisch gesehen handelte es sich um eine Festplattenverschlüsselung auf Basis von dm-crypt. Insbesondere bei diesen tieferen Bereichen von Android merkt man oft die Linux-Basis, denn letztlich ist das nicht viel anderes als die LUKS-Vollverschlüsselung bei Linux.
Technisch war das natürlich etwas aufwendiger. Die Verschlüsselung erfolgte in der üblichen Blockdevice-Methode, bei der die gesamten Userdata-Partition verschlüsselt wurde. Die Verschlüsselung erfolgte mit einem einzigartigen Schlüssel, der gleichermaßen an den Benutzer-PIN gebunden und mittels TEE signiert wurde. Mit diesem Schlüssel wurden jene Bereiche verschlüsselt, in denen Android Benutzerdaten speichert.
Es gab nur ein grundlegendes Problem. Bei einem Neustart des Android-Smartphones waren viele Funktionen nicht verfügbar, bevor der Anwender seine Passphrase eingegeben hatte. Beispielsweise Wecker oder auch Telefonanrufe. Das war natürlich für ein Smartphone-Betriebssystem keine zufriedenstellende Lösung.
Diese Lösung steht nach einer längeren Übergangsphase nicht mehr zur Verfügung. Android ab Version 10 nutzt nur noch die FBE-Methode.
FBE: File Based Encryption
Um diese Beschränkungen zu beheben, hat Google ab Android 7 die dateibasierte Verschlüsselung (FBE) eingeführt. Dabei handelte es sich um eine Neuentwicklung auf Basis des für Android verwendeten Dateisystems ext4. Die Umstellung hat je nach OEM-Hersteller etwas gedauert, weshalb zwischen den Versionen 7 und 9 die Verschlüsselung je nach Konfiguration und Hersteller unterschiedlich funktioniert hat, aber heute ist FBE die Standardverschlüsselung.
Ein netter Nebenaspekt: Diese Erweiterung des ext4-Dateisystems zog mit Kernel 4.1 bzw. 4.6 (fscrypt) direkt upstream ein und kommt dadurch allen Linux-Anwendern zugute. Die Adaption verzögerte sich hier etwas, aber mit systemd-homed steht nun erstmals eine praktikable Umsetzung für den Linux-Desktop zur Verfügung.
Technisch gibt es zwei Bereiche. Den Standarspeicherplatz (Credential Encrypted = CE), der erst nach der Entschlüsselung zur Verfügung steht und den sogenannten Device Encrypted (DE) Speicher, der während des Direct Boot-Verfahrens Anwendungen ermöglicht mit begrenztem Datenzugriff zu funktionieren.
Anfänglich war ein Nachteil der FDE-Methode die fehlende Verschlüsselung der Metadaten (Berechtigungen, Dateigröße, Verzeichnis-Layout etc.). Diese berechtigte Kritik – z. B. in diesem Short Paper – kann man auch heute noch häufiger lesen, wenn es um Android-Verschlüsselung geht. Das Problem hat Google in Android 9 behoben und es ist somit nicht mehr aktuell.
Der wesentliche Unterschied für den Anwender: Mit FBE gesicherte Android-Geräte booten ganz normal in den Sperrbildschirm und bieten dort auch vor der Entschlüsselung durch den Anwender Funktionalitäten wie Anrufe, Wecker etc.
Aktivierung durch den Anwender
Sobald der Anwender einen PIN, eine Passphrase und/oder biometrische Merkmale hinterlegt hat, ist die Verschlüsselung aktiviert. Normalerweise geschieht dies bereits bei der Initialisierungsroutine. Anwender müssen mehrfache Warnungen überspringen, um ihre Geräte ohne entsprechenden Schutz nutzen zu können. Das ist meiner Ansicht nach die richtige Vorgehensweise. Überprüfen lässt sich der Status in den Einstellungen und Sicherheit und dort in Verschlüsselung und Anmeldedaten.
Hier ist wie aus dem folgenden Screenshot bei „Smartphone verschlüsseln“ der Status Verschlüsselt zu sehen. Weitere Einstellungsmöglichkeiten oder Handlungsbedarf bestehen nicht.
In den vergangenen Wochen haben wir unterschiedliche Linux-Distributionen auf Einsteigertauglichkeit getestet. Dabei kamen zuvor definierte Bewertungskriterien zum Einsatz.
Folgende Distributionen konnten wir in unsere Tests einbeziehen:
Natürlich stellt die Auswahl nur einen Bruchteil der verfügbaren Linux-Derivate dar. Dennoch vermittelt sie ein gutes Gesamtbild über den aktuellen Stand der Entwicklungen.
Grundsätzlich lassen sich die Distributionen in drei Bereiche aufteilen. Dazu gehören einerseits klassische Ansätze wie bei openSUSE Leap, Ubuntu LTS, Debian GNU/Linux oder ZorinOS, andererseits Rolling-Release Lösungen wie Siduction, Manjaro oder openSUSE Tumbleweed. Fedora Silverblue verfolgt als einzige Immutable Distribution in unseren Tests neue Wege und bietet aufgrund der Stabilität und reibungslosen Updatefähigkeit ein ideales System für Einsteiger.
Davon unabhängig eignen sich alle vorgestellten Lösungen gut für einen ersten Kontakt mit dem Freien Betriebssystem. Teilweise unterstützen Assistenten oder Handbücher bei der Einarbeitung.
Fast alle getesteten Distributionen sind mit den drei grossen Desktop-Umgebungen, KDE-Plasma, GNOME-Shell und Xfce verfügbar. Obwohl wir nur jeweils eine Desktop-Variante getestet haben, sollte diese nicht den Ausschlag für die Wahl eines Einsteigers geben. Alle drei Umgebungen sind gut für Um- oder Einsteiger geeignet. Hier liegt es am persönlichen Geschmack, was einem besser gefällt.
Möchte man ein System haben, welches man einfach nur benutzen kann, ohne sich tiefer mit den Konzepten von Linux auseinanderzusetzen, ist Fedora Silverblue oder ZorinOS eine gute Wahl. Siduction hingegen bietet ausführliche Dokumentationen und Anlaufstellen bei Fragen an. Ambitionierte Einsteiger können zu Manjaro oder openSUSE Tumbleweed greifen. Und wer Linux von der Basis ab kennenlernen möchte, dem sei ein Blick in den Slackware basierten Linux-Kurs empfohlen.
Die MZLA Technologies Corporation hat mit Thunderbird 91.6 ein planmäßige Update für seinen Open Source E-Mail-Client veröffentlicht.
Neuerungen von Thunderbird 91.6
Mit dem Update auf Thunderbird 91.6 hat die MZLA Technologies Corporation ein planmäßiges Update für seinen Open Source E-Mail-Client veröffentlicht und behebt damit aktuelle Sicherheitslücken. Darüber hinaus bringt das Update diverse Fehlerbehebungen der Versionsreihe 91, welche sich in den Release Notes (engl.) nachlesen lassen.
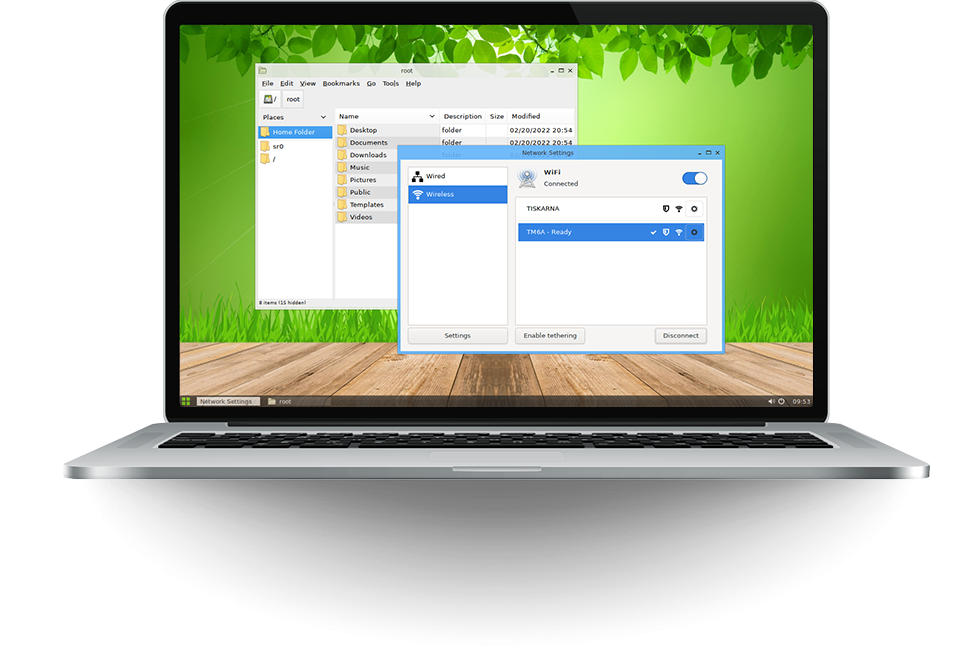








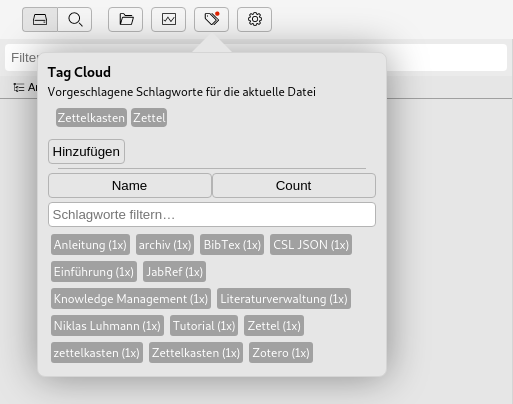


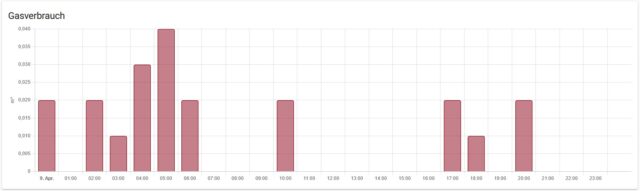
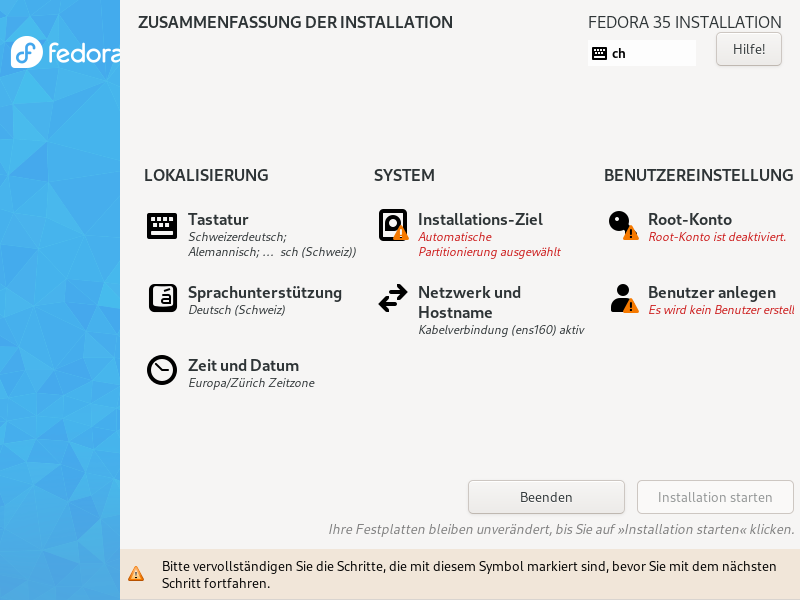


{kind=link}