Seid ihr Windows satt? Dann gehört ihr zur wachsenden Gruppe von Anwender:innen, die umsteigen.
Seit Monaten sehe ich in Social Media viele Leute, die von Windows auf Linux umsteigen möchten. Die Gründe dafür sind vielfältig:
- Am 14. Oktober 2025 endet der Support für Microsoft Windows 10
- Microsoft ist in den letzten Monaten/Jahren durch viele Verfehlungen aufgefallen
- Windows 11 verlangt neue Hardware
- Windows 11 bringt Werbung im Betriebssystem
- Windows 11 nimmt mit der Anwendung Recall alle paar Sekunden euren Bildschirm auf
- und so weiter, uns so fort
Manche Anwender:innen sind es auch einfach satt, sich von Microsoft gängeln zu lassen und wünschen sich ein freies und selbstbestimmtes Betriebssystem und Anwendungen für ihren täglichen Gebrauch.
Dieser Artikel richtet sich an Personen, die IT-technisch keine Ahnung von nichts haben. Ich versuche den Umstieg von Windows zu Linux so einfach wie möglich zu beschreiben.
Deine persönliche Einstellung zählt
Wer umsteigen möchte und dabei dasselbe wie vorher erwartet, hat von Anfang an verloren. Windows ist nicht Linux, ist nicht MacOS, ist nicht Android, ist nicht iOS. Der Wechsel des Betriebssystems (und dazu gehört auch die grafische Erscheinung und Bedienbarkeit der Oberfläche sowie die Anwendungen) erfordert eine offene Haltung für Neues. Wer mit Freude und Entdeckergeist den Umstieg in Angriff nimmt, hat gewonnen.
Die grosse Vielfalt
Windows ist nur Windows, macOS ist nur macOS - bei beiden Betriebssystemen gibt es keine Auswahl. Leute, die nicht sehr mit Computern vertraut sind, empfinden diese fehlende Auswahl eher als positiv. Bei Linux werdet ihr das Gegenteil erleben. Es gibt Hunderte Linux-Distributionen, ein Dutzend Benutzeroberflächen und viele alternative Anwendungen für denselben Zweck. Das ist kein Nachteil, sondern eine Bereicherung.
Was ist eine Linux-Distribution?
Eine "Distro" kommt immer als Gesamtpaket daher, in dem das Betriebssystem, eine oder mehrere Benutzeroberflächen, eine Vorauswahl von Anwendungsprogrammen und eine bestimmte Abstimmung aller Komponenten geliefert wird. Die Distro deiner Wahl liefert ein Gesamterlebnis ab, mit dem dein Computer ohne weiteres Zutun nutzbar ist.
Was ist eine Benutzeroberfläche?
Im Gegensatz zu Windows und macOS gibt es bei Linux viele unterschiedliche Benutzeroberflächen, aus denen du diejenige auswählen kannst, die deinem Geschmack und deiner Arbeitsweise am besten entspricht. Fast alle Distros bieten mehrere Benutzeroberflächen zur Auswahl an.
Wie funktioniert das mit den Anwendungen?
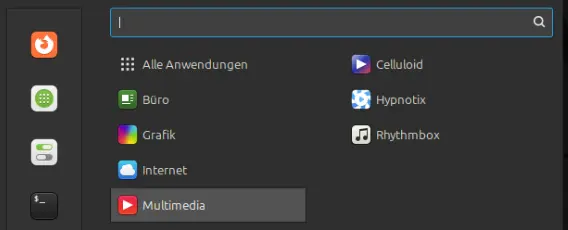
Kennst du den App-Store vom iPhone oder den Play-Store auf dem Android-Handy? Genauso kannst du es dir bei Linux vorstellen. Es gibt eine zentrale Anwendungsverwaltung. Dort kannst du Anwendungen suchen, installieren oder deinstallieren. Diese Anwendungsverwaltung (Paket-Manager) kümmert sich um die Aktualisierung des gesamten Betriebssystems und aller Anwendungen. Du musst nie wieder aus dem Internet EXE-Dateien herunterladen oder dubiose Anwendungen abonnieren. Die Paket-Manager liefern geprüfte Software und verwalten sie für dich.
Wie finde ich die richtige Linux-Distribution?
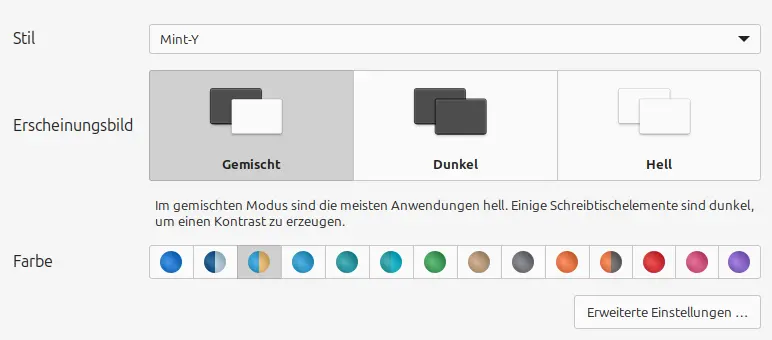
Als Einsteiger:in sollte euch die Distro egal sein, weil fast alle gut sind. Viel wichtiger für den ersten Eindruck und das Arbeitserlebnis ist die Benutzeroberfläche. Das ist das, was ihr seht und womit ihr arbeitet. Ihr könnt euch überlegen, ob ihr lieber eine klassische oder moderne Arbeitsumgebung haben möchtet. Oder ob ihr mehr auf das Aussehen von Windows oder macOS steht. Manche Oberflächen (KDE-Plasma, GNOME) brauchen mehr Power, andere sind gut für alte Hardware geeignet (Xfce, Mate, Lxqt).
Die grossen Benutzeroberflächen
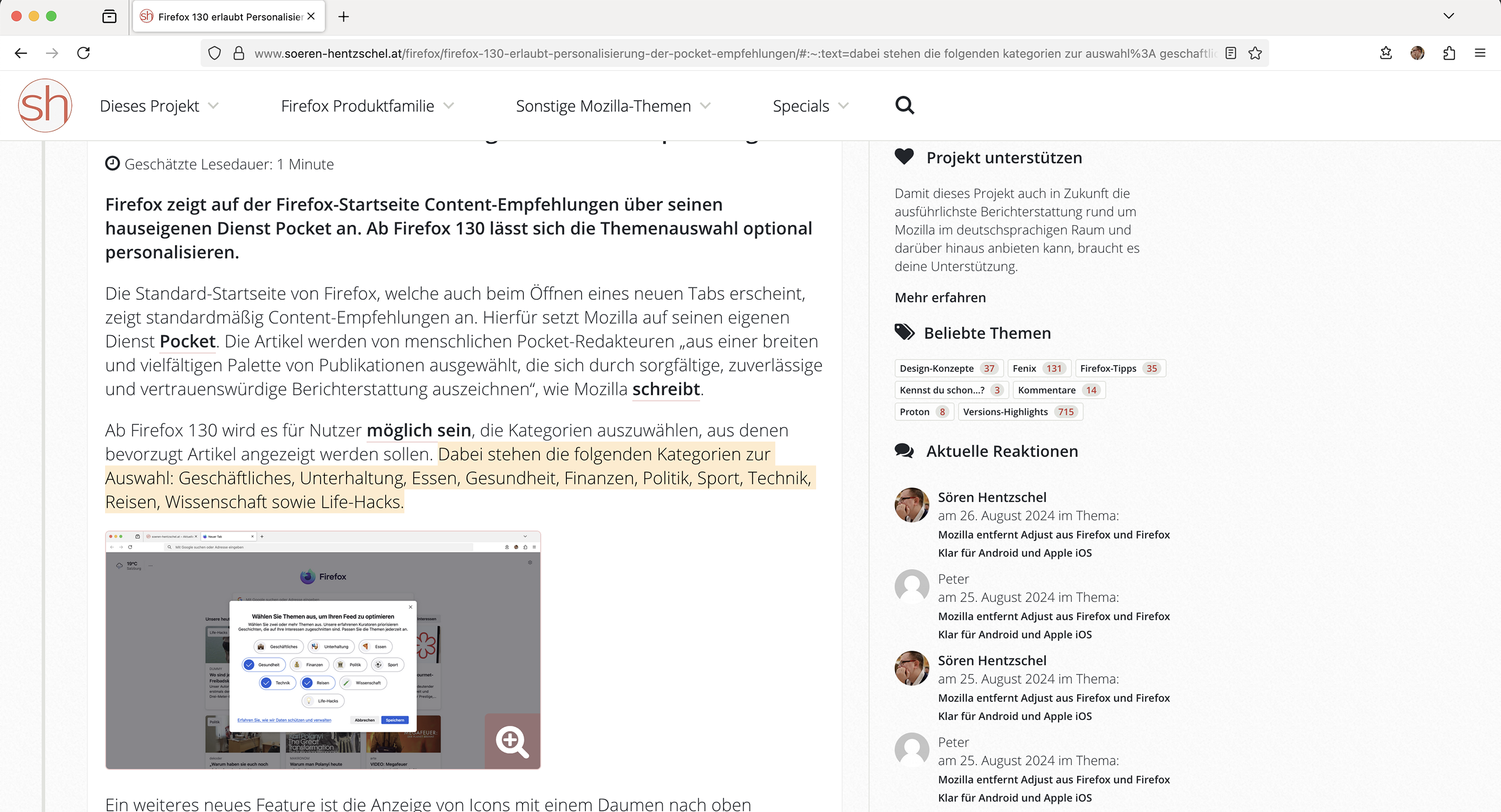
Es gibt zwei grosse und populäre Linux-Benutzeroberflächen: KDE-Plasma und GNOME. Hier seht ihr Bilder davon:
KDE-Plasma
GNOME
KDE-Plasma lehnt sich eher an Windows an und hat sehr viele Einstellmöglichkeiten. Die GNOME-Benutzeroberfläche erinnert ein wenig an macOS und bietet weniger Einstellmöglichkeiten. Beide Optionen sind den Angeboten von Windows und Apple weit voraus; sie sind der technische Status quo, wenn es um Funktionalität und Benutzerfreundlichkeit geht.
Die beiden Fotos sagen sehr wenig aus. Daher empfehle ich euch, aktuelle Videos zu KDE-Plasma und GNOME anzuschauen, um einen besseren Eindruck zu erhalten. Wenn ihr im Internet danach sucht, findet ihr viele Eindrücke und Testberichte. Achtet bitte darauf, dass ihr aktuelle Videos anschaut, die in den letzten Monaten aufgenommen wurden. Auch zu den leichtgewichtigen Desktops findet ihr Videos.
Die grossen Distributionen
Wie im letzten Kapitel erwähnt, ist die Wahl der Distribution für Ein- und Umsteiger:innen nebensächlich. Ein Kriterium bei den Distros ist der Update-Zyklus, also wie oft ihr Aktualisierungen erhaltet. Ganz grob wird dabei zwischen "Stabil" und "Rollend" unterschieden. Das stabile Modell erneuert eure Anwendungen ca. einmal pro Jahr, während ihr beim rollenden Modell kontinuierlich Aktualisierungen erhaltet. Davon ausgenommen sind Sicherheits-Aktualisierungen, die in beiden Modellen ständig ausgeliefert werden.
Ich empfehle euch, ein stabiles Modell zu wählen.
Zu den bekanntesten Distributionen gehören:
Die grossen Distributionen sind nicht zwingend die besten für Einsteiger. Ich würde keine davon für Anfänger:innen empfehlen. Stattdessen rate ich zu Linux Mint. Diese Distribution basiert auf Ubuntu, welches wiederum auf Debian aufbaut. Mint verwendet weder KDE-Plasma noch GNOME als Benutzeroberfläche, sondern den Cinnamon-Desktop.
Cinnamon-Desktop
Mit dieser Oberfläche kommen alle zurecht, die schon einmal einen Computer bedient haben. Insbesondere haben Windows-Umsteiger damit keine Probleme. Falls euch das zu langweilig aussieht, könnt ihr Zorin Linux ausprobieren. Wem gutes Design wichtig ist, findet mit Zorin einen schönen Einstieg in die Linux-Welt.
Zorin-Desktop
Ausprobieren
Niemand möchte die Katze im Sack kaufen. Wobei "kaufen" hier das falsche Wort ist. Linux-Distributionen kann man kostenlos beziehen. Leider ist das für viele Leute ein wichtiger Faktor, wenn sie sich für Freie Software entscheiden. Tatsächlich steht nirgendwo geschrieben, dass Freie Software kostenlos sein muss. Die Entwickler:innen von Freier Software müssen auch von irgendetwas leben.
Freie Software garantiert diese Vorteile:
- Verwenden, zu jedem Zweck
- Verbreiten, um andere teilhaben zu lassen
- Verstehen, um die Bildung zu unterstützen
- Verbessern, um die Sache voranzubringen
Wer eine Linux-Distro ausprobieren möchte, hat viele Möglichkeiten. Man kann die Distro auf einen USB-Stick speichern und damit booten. Fast alle Distributionen bieten einen Live-Modus an, in dem vom Stick gestartet wird, ohne etwas am installierten Betriebssystem zu ändern. Eine andere Möglichkeit bieten virtuelle Maschinen, in denen man unter Windows ein anderes Betriebssystem starten kann. Anfängern empfehle ich etwas anderes und viel Einfacheres. Auf der Webseite distrosea.com könnt ihr sehr viele Linux-Distributionen im Browser ausprobieren.

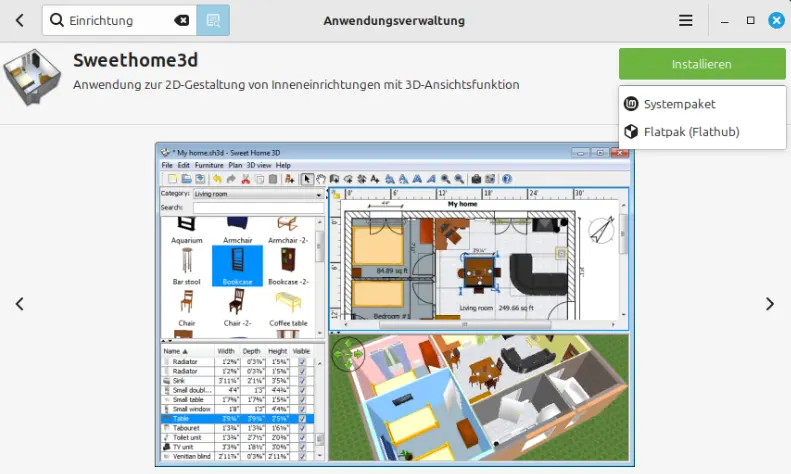
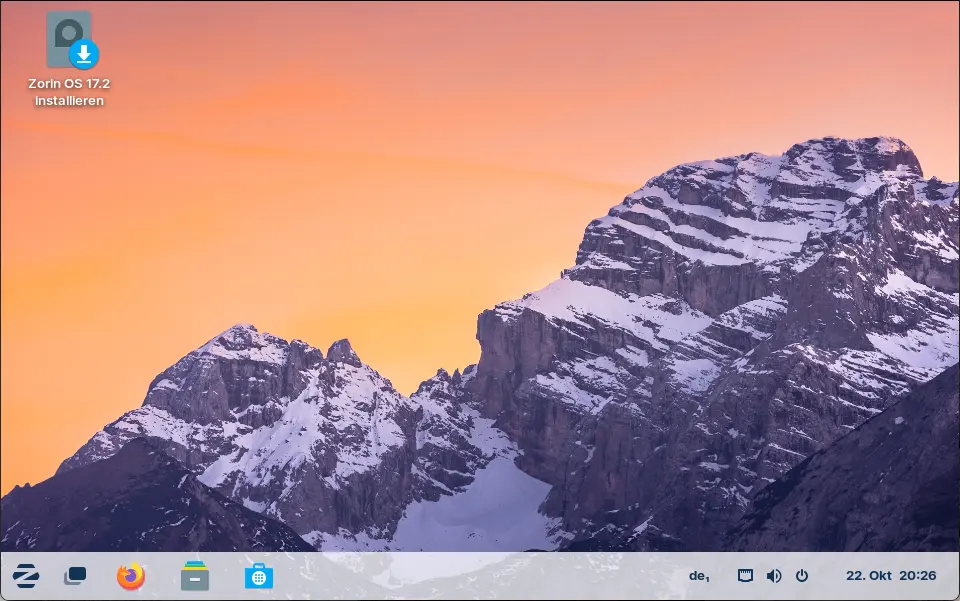
Am Beispiel von Zorin OS möchte ich euch zeigen, wie es funktioniert. Wenn ihr auf der DistroSea-Webseite ganz nach unten scrollt, findet ihr Zorin OS. Wenn ihr auf das Icon klickt, seht ihr eine Beschreibung dieser Distribution und diese Auswahl:
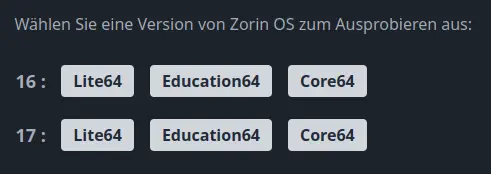
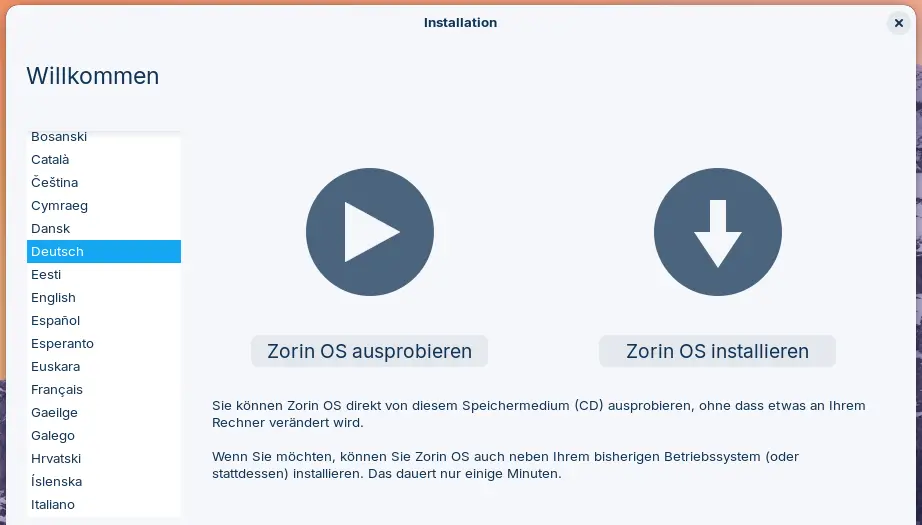
Dort wählt ihr die Version 17 und Core64 aus. Dann seht ihr einen "Bist du ein Mensch"-Dialog und könnt danach auf Start Zorin OS klicken. Ihr werdet dann in eine Warteschlange eingereiht, weil es noch andere Personen gibt, die diese Distro auf dem Server von DistroSea ausprobieren wollen. Normalerweise dauert es nicht lange, bis du an der Reihe bist. Sobald das der Fall ist, klickst du auf Weiter. Sodann startet der originale Installationsprozess des gewählten Betriebssystems. Bei Zorin OS wählt ihr die Sprache und klickt auf Zorin OS ausprobieren.
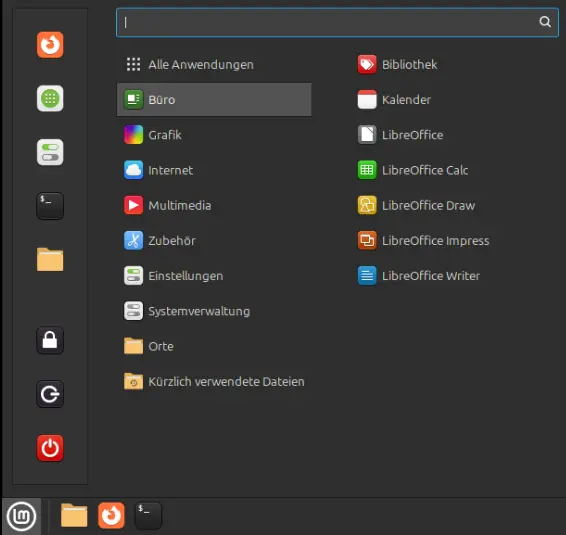
Nachdem Zorin im Ausprobieren-Modus gestartet ist, kannst du alles ausprobieren, was diese Linux-Distribution bietet. DistroSea stellt ein Menü auf der linken Seite zur Verfügung, mit dem du in den Vollbild-Modus schalten kannst. Damit füllt Zorin deinen gesamten Bildschirm aus.
Nachdem ihr euch verschiedene Distributionen angesehen habt, gibt es drei Möglichkeiten:
- Ihr testet die Distro eurer Wahl über einen längeren Zeitraum in einer virtuellen Maschine auf eurem bisherigen Betriebssystem. Da das bei den meisten Windows sein wird, empfehle ich die Installation von Oracle VirtualBox. Eine Anleitung dazu findet ihr hier. Anfänger können mit dieser Methode überfordert sein. Wer die Windows-Home-Edition hat, wird sich mit der Installation des Microsoft Visual C++ Redistributable herumschlagen müssen, bevor VirtualBox installiert werden kann.
- Eine Linux-Distribution kann als Dual-Boot neben eurem bestehendem Windows installiert werden. Auch hierfür findet man viele Anleitungen. Leider ist auch diese Variante nichts für Einsteiger.
- Man kann die Lieblings-Distro auf einem USB-Stick speichern und davon im Live-Modus booten, ohne das bisherige Betriebssystem zu beeinflussen. Das ist nicht schwierig, ist jedoch für einen monatelangen Testbetrieb nicht geeignet. Ein grosser Vorteil dieser Methode ist, dass ihr die Hardware-Kompatibilität testen könnt.
- Besorgt euch ein ausgedientes Notebook und installiert eure Distribution darauf. Das Vorgehen ist das gleiche, wie unter Punkt 3. beschrieben. Allerdings verwendet ihr nicht den Live-Modus, sondern installiert Linux tatsächlich. Dieses Vorgehen hat mehrere Vorteile: Ihr lernt den kompletten Installationsprozess kennen. Die Installation läuft auf echter Hardware. Wenn die Distribution auf dem "alten Hund" schnell genug ist, wird es auf eurem aktuellen Notebook nur noch besser.
Ja, was denn jetzt? Ich schlage eine Kombination von 3 und 4 vor. In beiden Fällen gilt es, die Distribution auf einem USB-Stick zu speichern. Das geht am einfachsten mit der Anwendung Etcher. Zuvor gilt es, die ISO-Datei der Distro herunterzuladen. Nehmen wir Linux Mint als Beispiel: Ihr geht auf die Download-Seite von Mint und sucht euch irgendeinen Download-Server aus. Sinnvollerweise nicht den in Papua-Neuguinea, sondern einen in eurem Land. Dann klickt ihr auf den Link und habt ein paar Minuten später die ISO-Datei in eurem Download-Verzeichnis liegen. Die heisst dann z. B. so: linuxmint-22-cinnamon-64bit.iso
Dann steckt ihr einen USB-Stick ein und startet Etcher. Die Bedienung muss ich hier nicht beschreiben; sie ist kinderleicht. Verwendet bitte einen frischen USB-Stick; uralte Sticks sind gerne mal kaputt.
Installieren
Nachdem die Distribution mit Etcher auf dem USB-Stick gespeichert wurde, könnt ihr euren aktuellen Rechner (oder den alten Hund) herunterfahren und neu starten. Der USB-Stick muss natürlich eingesteckt sein.
Ich habe schon Notebooks erlebt, die nur von bestimmten USB-Buchsen booten konnten. Falls ihr damit Probleme habt, steckt den USB-Stick in einen anderen Port und versucht es erneut.
Nun müsst ihr eurem Gerät erklären, dass es nicht von der Festplatte, sondern vom USB-Stick booten soll. Dafür gibt es zwei Möglichkeiten, die beide etwas nervig sind. Fast alle Geräte erlauben es, beim Starten ein Boot-Menü aufzurufen. Dafür gibt es eine nicht standardisierte Taste. Diese befindet sich immer in der oberen Reihe eurer Tastatur, also entweder ESC oder eine der F-Tasten. Entweder schaut ihr in die Beschreibung eures Gerätes oder sucht im Internet nach der richtigen Taste. Falls es bei euch kein Boot-Menü gibt, müsst ihr das BIOS-Menü aufrufen. Das geschieht ebenfalls über die ESC- oder eine der F-Tasten. Im Boot-Menü kann man mit den Cursor-Tasten auswählen, von welchem Massenspeicher gebootet werden soll (ihr wollt den USB-Stick). Im BIOS-Menü kann man die Boot-Reihenfolge auswählen. Dort könnt ihr einstellen, dass zuerst vom USB-Stick gebootet werden soll.
Soll ich jetzt noch beschreiben, wie man Secure-Boot abschaltet? Puh, ich lasse es sein.
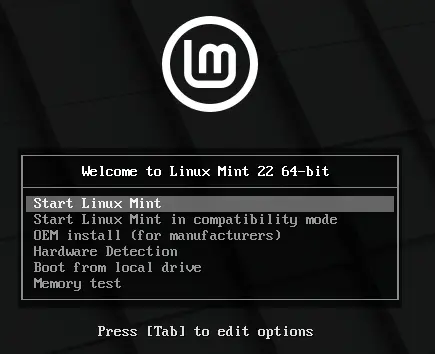
Sobald ihr es geschafft habt, dass euer Gerät vom USB-Stick bootet, ist das die halbe Miete. Zuerst würde ich den Live-Modus auswählen, um sich umzusehen und um die Hardware-Erkennung zu testen. Wenn das gut aussieht, könnt ihr entweder im Live-Modus bleiben (siehe oben bei 3.) oder die tatsächliche Installation anstossen. Dafür gibt es in der Regel ein Icon "Installieren" auf dem Desktop (siehe oben bei 4.)
Nun könnt ihr den Installationsprozess eurer Distro geniessen und beurteilen. Während der Installation müsst ihr ein paar Angaben machen, die alle selbsterklärend sind (ausser bei den die-hard Distros). Nach Abschluss der Installation werdet ihr zum Neustarten aufgefordert.
Dann beginnt das Entdecken eurer neuen GNU/Linux-Distribution. Viel Spass dabei!
Im zweiten Teil des Artikels "Von Windows zu Linux umsteigen", beschreibe ich alles, was man nach der erfolgreichen Installation machen kann. Der dritte Teil handelt von den mitgelieferten Anwendungen.
Schönes Wochenende ☀️
Titelbild: https://wallpaperaccess.com/full/1875475.jpg
Quellen: stehen alle im Text
GNU/Linux.ch ist ein Community-Projekt. Bei uns kannst du nicht nur mitlesen, sondern auch selbst aktiv werden. Wir freuen uns, wenn du mit uns über die Artikel in unseren Chat-Gruppen oder im Fediverse diskutierst. Auch du selbst kannst Autor werden. Reiche uns deinen Artikelvorschlag über das Formular auf unserer Webseite ein.











{kind=link}