Vor ca. 2 1/2 Wochen habe ich mir die Alpha-Version von Ubuntu 8.04 Hardy Heron auf meinem Laptop installiert. Zeit für einen ersten Bericht.
Laut dem Release Schedule von Hardy wird am 20. März die Beta erscheinen, die Final ist dann für den 24. April 2008 geplant. Noch ist Hardy also Alpha, was man auch ab und zu mal merkt!  Während der Zeit, in der ich Hardy installiert habe gab es einmal einen verkrüppelten Kernel (kein WLAN, kein Sound…) und eine Bibliothek (glibc), die das ganze System nicht mehr starten ließ. Es dauert natürlich normalerweise nur einen oder zwei Tage bis die Pakete aktualisiert sind. Jedoch - und deshalb nach wie vor meine “Warnung” vor Alpha-Versionen von Ubuntu, es kann tatsächlich mal sein, dass das System nach einem Update nicht mehr funktioniert. Wer davor Panik hat, kein zweites stabiles System auf dem Rechner hat oder nen zweiten Computer, sollte immer daran denken. Aber ihr wisst ja sicher selber am besten, was “gut” für euch ist! *grins*
Während der Zeit, in der ich Hardy installiert habe gab es einmal einen verkrüppelten Kernel (kein WLAN, kein Sound…) und eine Bibliothek (glibc), die das ganze System nicht mehr starten ließ. Es dauert natürlich normalerweise nur einen oder zwei Tage bis die Pakete aktualisiert sind. Jedoch - und deshalb nach wie vor meine “Warnung” vor Alpha-Versionen von Ubuntu, es kann tatsächlich mal sein, dass das System nach einem Update nicht mehr funktioniert. Wer davor Panik hat, kein zweites stabiles System auf dem Rechner hat oder nen zweiten Computer, sollte immer daran denken. Aber ihr wisst ja sicher selber am besten, was “gut” für euch ist! *grins*
Und es ist ja tatsächlich so - wenn man ein System wirklich testen will, muss man auch tagtäglich damit arbeiten. Mal kurz in ner VM installieren und angucken ist gut für die Neugierde, aber richtig testen wie sich das OS so verhält, kann man damit sicher nicht. Ich habe deshalb mein wunderbar stabiles Gutsy mit der Alpha von Hardy ersetzt und benutze es nun täglich. Ich habe wirklich schon viel geflucht damit aber - ich liebe es. 
Wie ist es denn nun so?
Hardy Heron wird ja wieder ein LTS-Release sein. Besonders deshalb gibt es auf den ersten Blick auch keine weltbewegenden Neuerungen. Man kann sich im englischen und deutschen Wiki durchlesen was es insgesamt alles Neues gibt. Ich will jetzt nur ein paar Sachen davon vorstellen, die ich auch persönlich verwende.
Um es mit in Fußballer-Art zu sagen: so rein vom “feeling” her fühlt sich Hardy sehr gut an. Irgendwie flüssiger und schneller als Gutsy. Ich bin mir selber nie sicher, ob das jetzt nur persönliche Einbildung ist oder Tatsache. Ich persönlich sitze nie mit ner Stoppuhr da und messe nach, wie lange das System zum booten oder eine Anwendung zum Starten braucht.
Grafischer Schnickschnack
Als glücklicher Besitzer einer Nvidia-Karte (GeForce Go 7300) habe ich wie bisher auch, mit der Grafik keinerlei Probleme. Nach Installation des Nvidia-Treibers (bei mir nvidia-glx-new, momentan Version 169.12) über den Restricted Manager wurde nach einem Neustart automatisch Compiz aktiviert. Ohne irgendwelche händische Nacharbeit an der xorg.conf (an der ich durchaus nacharbeiten musste, nur nicht für Compiz, dazu später mehr). Leider wird ein gutes Tool zum konfiguren von Compiz immer noch nicht automatisch installiert. Deshalb dafür bitte immer noch das Paket
compizconfig-settings-manager
nachinstallieren, in dem ihr alles nach Herzenslust einstellen könnt. Was gibt es dazu noch zu sagen… Compiz hat bei mir unter Gutsy problemlos funktioniert und tut das nach wie vor unter Hardy. Jedoch muss ich gestehen, dass ich Compiz mittlerweile die meiste Zeit deaktiviert habe. Aber zum Angeben vor Windows-Usern ist das natürlich immer noch das Beste….
Ach ja, so nebenbei zum nvidia-glx-new Treiber. Das Paket “nvidia-settings” muss nun händisch nachinstalliert werden und ist kein Bestandteil des Treibers mehr. Der Menüeintrag ist dann unter “System > Systemverwaltung > NVIDIA X Server Settings” zu finden. Wollt ihr damit auch wirklich auch etwas einstellen, müsst ihr “nvidia-settings” natürlich mit Root-Rechten starten… logisch, oder?
Artwork
Das Gutsy Artwork ist leicht überarbeitet, aber noch in den Ubuntu-typischen braun-orange Tönen gehalten. Das tolle Wallpaper habt ihr ja schon in meinem letzten Eintrag sehen können. Ich liebe diese Farben ja und hoffe, dass sie auch für das final Release so bleiben. Aber beim Artwork kann es schon durchaus sein, dass noch sehr spät Änderungen hochgeladen werden, man darf also gespannt sein. Das alles jetzt schwarz-orange wird, denke ich aber mal nicht! Aber wer weiß das schon so genau…
Metacity mit Desktopeffekten
Mit Hardy haben wir ja Gnome 2.22.0 (und bei Kubuntu KDE 3. irgendwas… keine Ahnung, aber noch nicht 4 standardmäßig…). Beim Fenstermanager Metacity gibt es mit dem neuen Gnome nun eine Neuerung. Metacity besitzt nun selber einen Composite-Manager, d. h. es können (ein passender Grafikkartentreiber vorausgesetzt) Desktopeffekte ohne Compiz dargestellt werden. Bisher ist das Ganze aber noch sehr in den Anfängen, viel gibt es noch nicht und einstellen kann man auch noch nichts, aber immerhin.
Aktivieren kann man die Effekte über das Terminal mit dem Befehl
gconftool-2 -s --type bool /apps/metacity/general/compositing_manager true
und deaktivieren logischerweise dann mit
gconftool-2 -s --type bool /apps/metacity/general/compositing_manager false
 Wie gesagt gibt es noch nicht sehr viel: Schatten unter Fenster und Menüs, echte Transparenz des Terminals, Fenstervorschau beim Umschalten mit Alt+Tab (jedoch nur vom aktiven Desktop wie es scheint). Und beim klicken auf ein Icon im Panel gibt es diesen lustigen Effekt wie beim Compiz auch.
Wie gesagt gibt es noch nicht sehr viel: Schatten unter Fenster und Menüs, echte Transparenz des Terminals, Fenstervorschau beim Umschalten mit Alt+Tab (jedoch nur vom aktiven Desktop wie es scheint). Und beim klicken auf ein Icon im Panel gibt es diesen lustigen Effekt wie beim Compiz auch.
Alles in allem noch nicht sehr viel, aber schonmal ein guter Anfang. Allerdings wird auch hier ein passender Grafikkartentreiber voraussgesetzt. D.h. wenn ihr diese Effekte nutzen könnt, könnt ihr theoretisch auch gleich Compiz einsetzen. Recourcenschonender sind die in Metacity eingebauten Effekte sicher. Aber alles noch etwas hakelig, aber probiert es einfach mal selber aus.
Weiter Infos dazu könnt ihr auch hier nachlesen.
Gnome Weltzeituhr
 Ein wirklich nettes neues Feature ist die Weltzeituhr in der Gnome-Uhr.
Ein wirklich nettes neues Feature ist die Weltzeituhr in der Gnome-Uhr.
Hier kann man einfach verschiedene Orte hinzufügen und sieht dann gleich auf den ersten Blick die Uhrzeit. Die verschienden Orte können jeweils als Zeitzone für den Computer eingestellt werden. Wenn man das tut, hat man neben dem Datum auch gleich eine Temperaturanzeige. Wirklich nett.
Gnome System Monitor
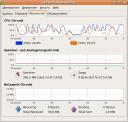 Der Systemmonintor überarbeitet und zeigt die Recourcen nun in schöner Cairo-Graphik.
Der Systemmonintor überarbeitet und zeigt die Recourcen nun in schöner Cairo-Graphik.
Da ich darauf wirklich öfters mal schaue, hat mich die optische Überarbeitung durchaus begeistert.
Sonstiges und Programme
Standardmäßig wird bei Hardy Alpha bereits der Firefox 3 installiert, im Moment in der Version 3 Beta 4. (Version zwei ist in den Quellen verfügbar und kann parallel installiert werden.). Ja, Firefox 3 ist was tolles. Jetzt nicht Ubuntu-spezifisch, so allgemein. Ich liebe ihn - noch schneller, bessere Lesezeichenverwaltung, intelligente Lesezeichen usw. Geschmeidig und macht Spaß.
Gnome hat jetzt endlich auch ein ordentliches CD-Brennprogramm standardmäßig installiert: Brasero. Hat alles, was ich brauche, somit fällt das zusätzliche installieren K3b (inkl. dessen massig Biliotheken) weg. Finde ich gut.
Für alles andere bitte ich einfach mal die oben genannten Wikis durchzustöbern… Interessant dürfte z. B. der Wubi-Installer sein, der Ubuntu von Windows aus installieren kann. Wie gesagt ich verweise nochmals auf das englische und deutsche Wiki.
Probleme beim Touchpad/der Maus
Per default konnte ich mit meine Touchpad nicht scrollen. Und die Maus zickte. Ich habe händisch in der Xorg.conf noch eine Ergänzungen vorgenommen. Ich habe den Block “Server Layout” hinzugefügt, der bei mir gänzlich gefehlt hat und bei Maus-Block Ergänzungen vorgenommen. Komisch irgendwie, dass das nicht automatisch drinstand. Ist das jetzt immer noch so, weiß das jemand?
So sieht meine xorg.conf jetzt aus. Und mit der klappt auch alles wunderbar jetzt.
Regressions?
Für mich gibt es nur eine Sache, die unter Gutsy tadellos funktioniert hat und jetzt nicht mehr. Einige Fn-Tasten gehen nicht mehr. Ich kann kann wie gehabt Bildschirmhelligkeit und Lautstärke mit den Fn- bzw. Multimedia-Tasten bedienen. Jedoch der das öffnen des CD-Fachs klappt nicht mehr, sowie das deaktivieren/aktivieren meines WLANs über die Fn-Kombinationen. Damit muss ich mich wohl noch näher beschäftigen.
Fazit
Hardy wird gut. 
Ich bin gespannt, was sich die nächsten Wochen noch so alles tut. Ach ja, die Lokalisation ist natürlich noch nicht abgeschlossen, weswegen z. B. der Firefox 3 in englisch daherkommt.